The Curious Case of OpenAI's Unsupervised Sentiment Neuron

The Curious Case of OpenAI's Unsupervised Sentiment Neuron
A nifty thing happened unintentionally, and some people overreacted
Not a particularly big story, but one that nicely exemplifies how media coverage of AI research goes wrong.
What Happened
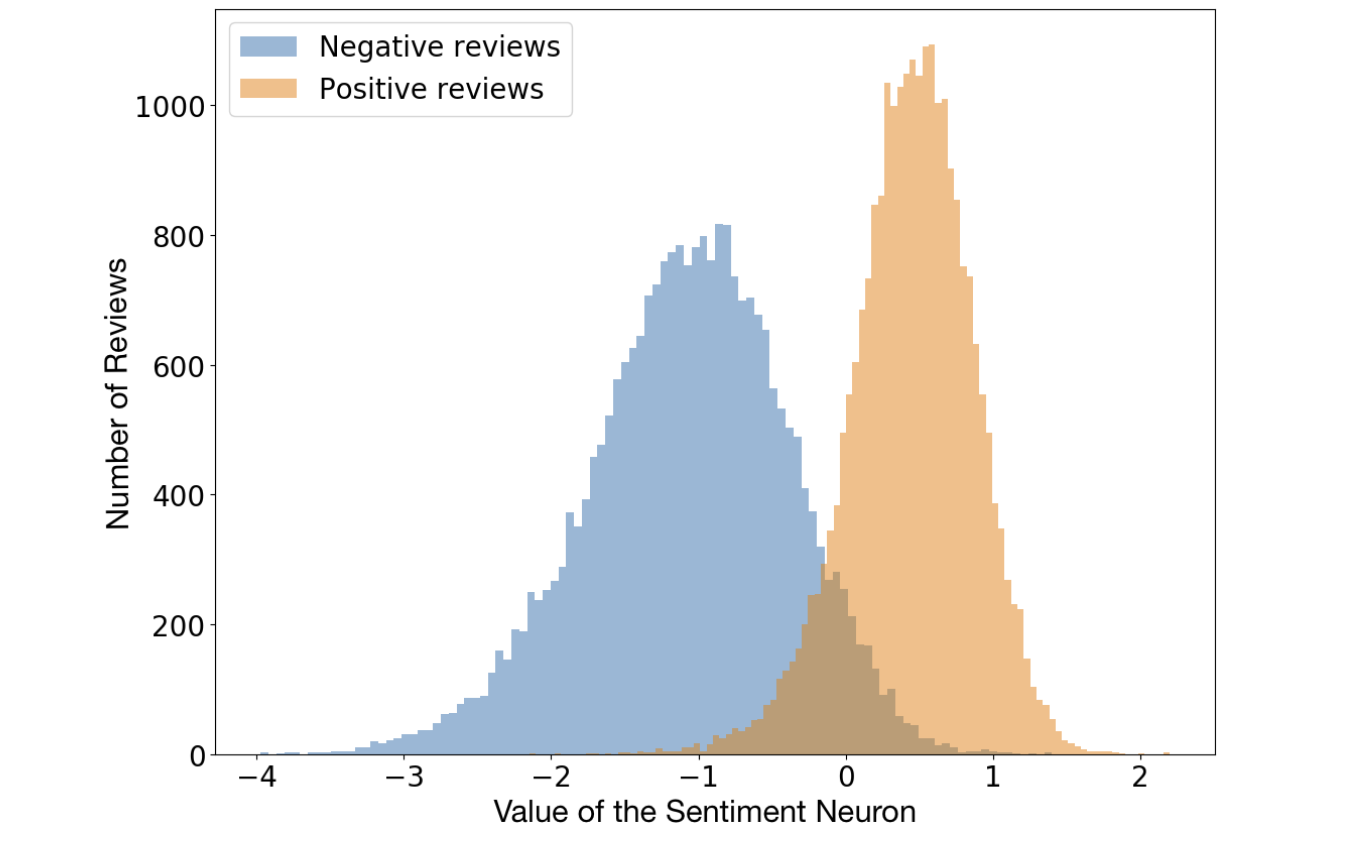
OpenAI’s own blog posts summarizes it nicely with “We’ve developed an unsupervised system which learns an excellent representation of sentiment, despite being trained only to predict the next character in the text of Amazon reviews”. In other words, they
- (A) learned a representation of text through training a next-character prediction model in an unsupervised fashion (without needing any other data beyond the text itself) and
- (B) showed that this representation captures wherether the text is negative or positive well because it can be used for supervised training of state of the art models for sentiment classifiction (trained on some text labeled as either negative or positive, the model can classify any text as being negative or positive).
This is a good result, though it should be noted that representation learning is a common use of unsupervised learning and the approach of pretraining a model on a lot of data (82 million Amazon reviews in this case) followed by supervised learning on less data is not at all novel.
The Reactions
Most egregiously, there was coverage that claimed that “An AI backed by Elon Musk just ‘evolved’ to learn by itself”. The source is certainly not a respectable news organization and the article itself is far more reasonable than the headline, but the headline is still mind-boggling in how ridicolous it is. More reasonable coverage covered it as “AI Learns to Read Sentiment Without Being Trained to Do So” and “Unsupervised AI Trains Itself How To Analyze Sentiment”. All these headlines make the sadly common mistakes of acting as if this computer program is an autonomous agent (“An AI”, “AI Learns”, “Unsupervised AI Trains Itself”) rather than an optimization problem rigged up entirely by human programmers that happened to have an unexpected side effect.
Our Perspective
Though all the news stories that covered this got the substrance of the research largely right, misleading headlines and agent-ification of computer programs is rampant in AI coverage. It should also be noted that the emergence of not-explicitly-trained for knowledge has been documented in papers before (“Object Detectors Emerge in Deep Scene CNNs” , “Emergence of Object-Selective Features in Unsupervised Feature Learning”). Plus, the data the unsupervised learning was done on was Amazon reviews, so it makes a whole lot of sense that sentiment was captured as part of the training. This is not to say the research is bad or not interesting, but rather that this sort of awareness of prior work and significance of results is sorely needed in AI coverage.
TLDR
OpenAI’s unsupervised learning result is cool, but the coverage of it exemplifies the common egregious faults with AI coverage as a whole.






