AlphaGo - so is Human Intelligence Obsolete?

AlphaGo - so is Human Intelligence Obsolete?
Breaking down the significance of the biggest AI story of the decade
Perhaps the defining media story for our current age of Deep-Learning AI wonders, this was deservedly considered a big deal but still deserves some scrutiny.
What Happened
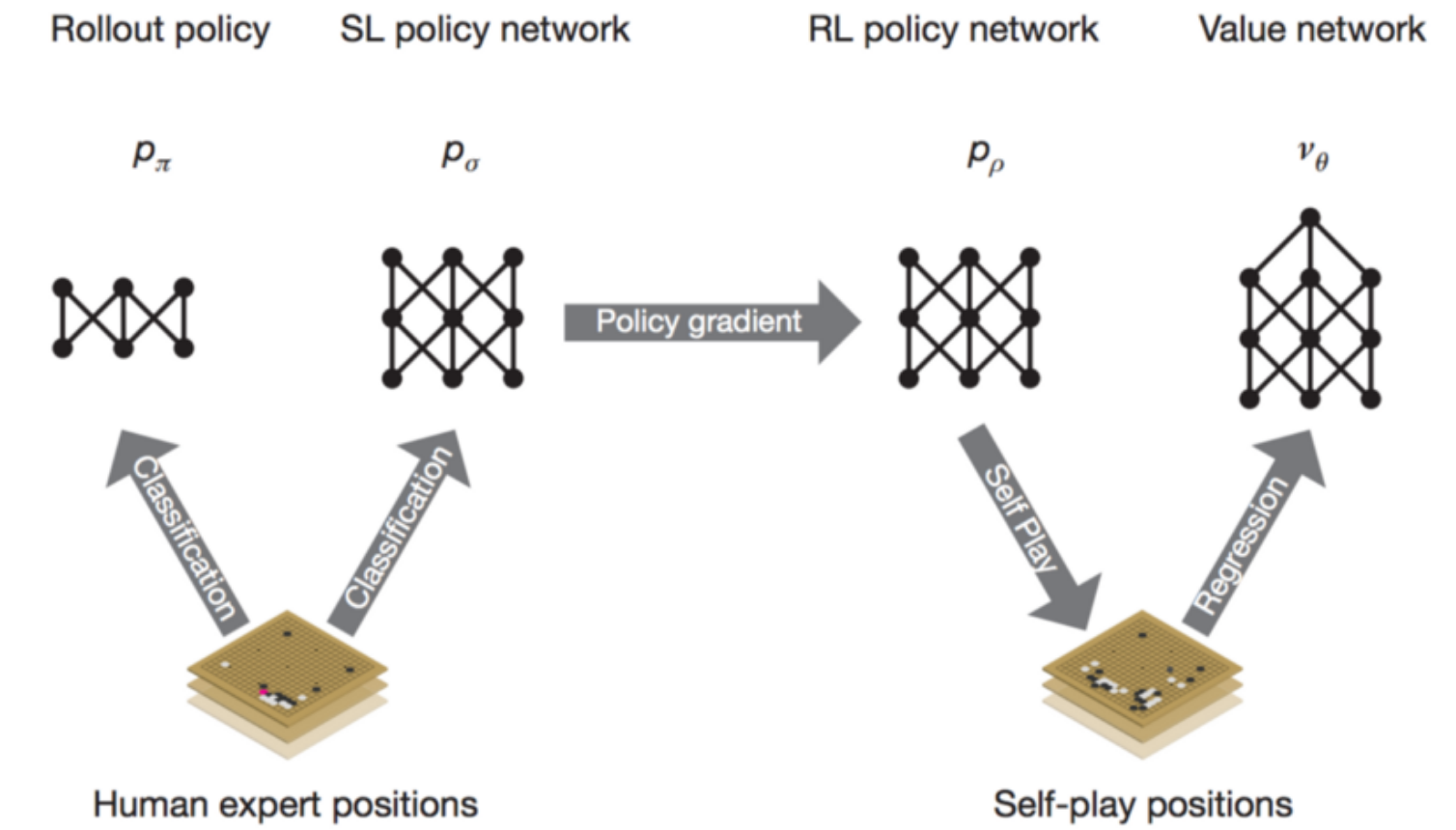
Aside from the media coverage, the research paper was a big event in itself when it was published in the presitigous Nature. The incredibely short summary is that researchers at Google got an AI to play Go astoundingly well by supercharging an already established state of the art approach to implementing Go playing programs. This approach, Monte Carlo Tree Search, was bolstered with a ‘policy network’ that can intelligently select the most promising moves to consider and a ‘value network’ that can evaluate how good a given Go position is.
This can be thought of a human having an intuitive sense for what moves to consider in their head when planning ahead, as well as having an intuitive understanding of how good a given position they might end up at is. The policy network was trained based on human Go games first, then fine tuned via self-play. After that, the moves generated by self-play were used to train the value network, and finally all the networks (and more) were used to improve the performance of the classic Monte Carlo Tree Search. It should be noted that the components of AlphaGo, Monte Carlo Tree Search and Deep Convolutional Neural Networks, had been applied to Go play by other researchers. But, the way AlphaGo combined these pieces was entirely novel and led to hugely impressive performance far better than anything achieved before.
You can read detailed in-depth takes on the content of the paper here or written by yours truly.
The Reactions
Understandably, this was great fodder for media coverage. As the paper itself said,
this is the first time that a computer Go program has defeated a human professional player [Fan Hui, a high ranking but not nearly best-of-the-best professional], without handicap, in the full game of Go
Like Deep Blue, it offered a simple and irresistible Man vs. Machine narrative, and Google was smart enough to do the no-brainer thing by setting it up exactly the same way by having AlphaGo play humanity’s best Go player, Lee Sidol, next. Lee Sidol lost 4 to 1, and the media was in agreement — Lee Sidol’s loss was a Big Deal:
- “Why is Google’s Go win such a big deal?”
- “This Is Why A Computer Winning At Go Is Such A Big Deal”
- “Why the Final Game Between AlphaGo and Lee Sedol Is Such a Big Deal for Humanity”
The gist of all this coverage is that AlphaGo is a Big Deal, and not just a retread of Deep Blue, because it did not win through brute computational force alone but rather through human-like learning of generalization and abstraction in the context of Go. Generalization and abstraction used to be the sole foray of humans, but AlphaGo proves beyond a doubt AI is starting to creep in on only-humans-can-do-this territory in a much more significant way than just being extremely capable at number crunching.
Our Perspective
The media coverage was not wrong in describing this as a historic feat for AI. But, it should be understood it is historic not just because of its value as AI research (many, many papers have been more influential and arguably more significant than AlphaGo) but also because of the engineering and PR prowess that went into that Lee Sidol match, and the immediate emotional and symbolic significance the outcome had. As Andrej Karpathy nicely summarized in “AlphaGo, in context”, “
AlphaGo is made up of a number of relatively standard techniques… However, the way these components are combined is novel and not exactly standard… On all of these aspects, DeepMind has executed very well. That being said, AlphaGo does not by itself use any fundamental algorithmic breakthroughs in how we approach RL problems
and then
Zooming out, it is also still the case that AlphaGo is a narrow AI system that can play Go and that’s it.
And that is precisely right. AlphaGo has not had a large impact of how non-Go related problems in AI are approached, and it’s human-like learning is typically unhuman in that it is limited to just the one extremely narrow task of playing Go. Furthermore, Go as a problem is broadly in the category of problems that are relatively easy to tackle with AI: it is deterministic, fully observable, easy to simulate, and has tons of available data of human games. In that sense, it is just the same as Chess - the number of totally moves is drastically larger and it is trickier to evaluate a position, but otherwise it is fair to claim it is an ‘easy’ type of problem’.
TLDR
Though definitely a huge accomplishment and rightfully a historic moment for AI, AlphaGo’s victory against Lee Sidol did not and does not mean human intelligence is obsolete. In fact, AlphaGo is narrowly designed for the task of playing Go extremely well, and its method cannot be extended to more complex AI tasks such as operating a robot. It is a testament to how far the field of AI has come, which is to say capable of creating AI programs that accomplish individual tasks that require human-like intelligence but not even close to cracking the problem of making AI capable of learning the breadth and depth of skills humans easily master.






