GPT-3: An AI Breakthrough, but not Coming for Your Job


GPT-3: An AI Breakthrough, but not Coming for Your Job
GPT-3 still has a range of limitations which must be noted before worrying that it will cost anyone their livelihood.

Image credit: Getty Images via The Guardian
Summary
- Recently, OpenAI released the largest language model to date, GPT-3, which is functionally similar to many of its predecessors and differentiated primarily by having 10x more parameters1 than the previous largest language model and being trained on a much bigger dataset.
- This large quantitative difference allows a trained GPT-3 to achieve qualitative improvements over its predecessors; unlike the latter, the trained GPT-3 model can perform many different tasks without training specifically for those tasks.
- It has met significant acclaim from both the press and technologists, who describe its myriad applications and also several key limitations.
- Although GPT-3 represents remarkable progress, its limitations have gotten less attention, and are summarized here.
What Happened
On May 28, OpenAI released the paper “Language Models are Few-Shot Learners,” which introduced GPT-3, the largest2 language model3 ever created. The 73-page paper describes how GPT-3 follows recent trends on significantly advancing the state of the art in language modeling. Broadly, on natural language processing (NLP) benchmarks, GPT-3 achieves promising, and sometimes competitive, results.
GPT-3 represents the increase in performance that comes from using a larger model, and it also follows the immense increases in model and data size that characterize recent developments in NLP. The paper’s core message however was less about its performance on benchmarks, and more about the discovery that due to its scale GPT-3 is capable of solving NLP tasks that it has never before encountered after seeing just one or a few examples of the task (‘few-shot’ learning). This is in contrast to what is typically done today, which is that models are re-trained (or ‘fine-tuned’) on a larger amount of additional data in order to perform new tasks.
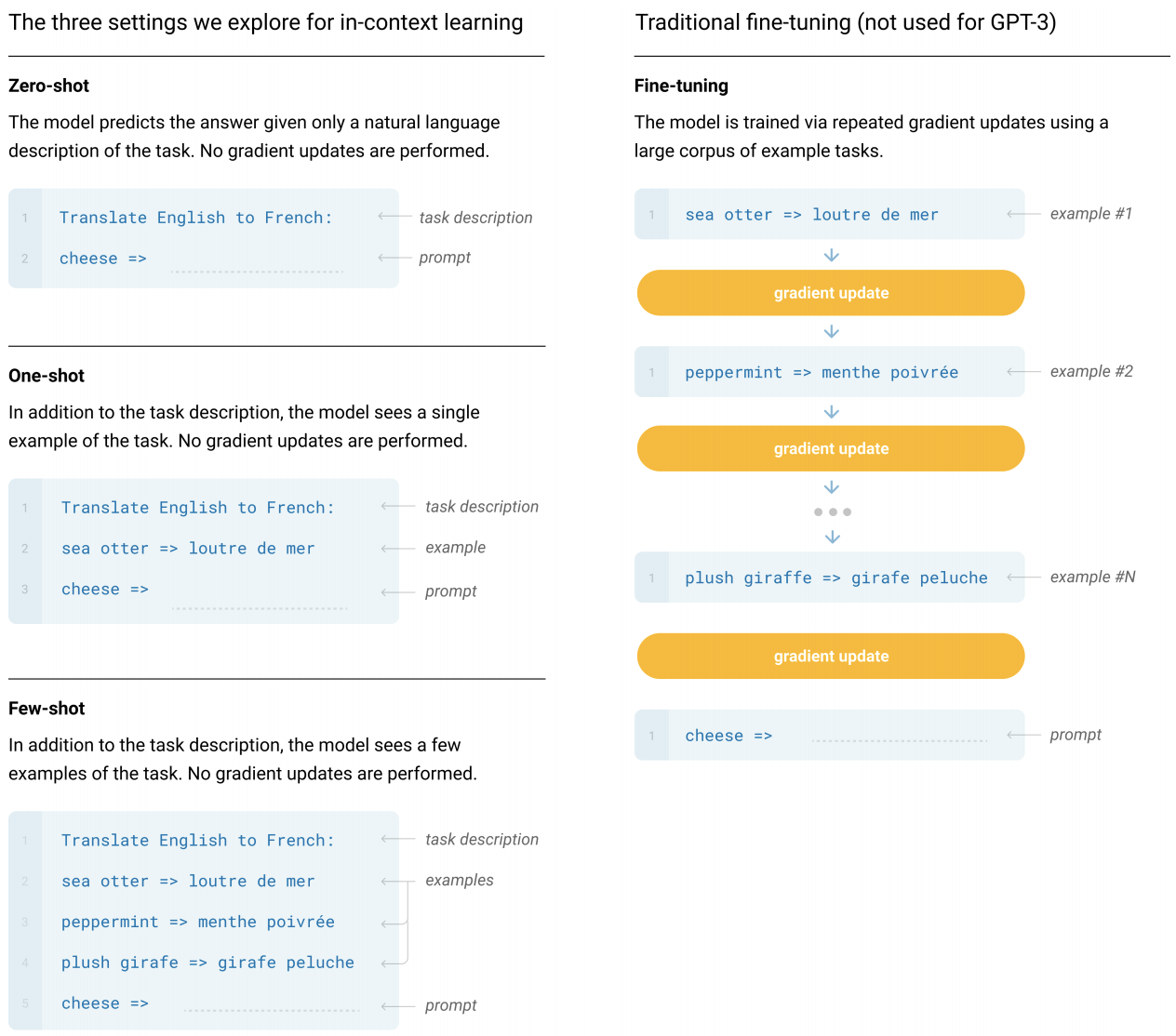
Last year, OpenAI developed GPT-2, which was able to generate long, coherent texts that, on first glance, are difficult to distinguish from human writing. OpenAI notes that they “use the same model and architecture as GPT-24, but the size of the network itself, as well as the data that it was trained on5, is much larger than its predecessor – GPT-3 has 175 billion parameters compared to GPT-2’s 1.5 billion, and was trained on 570 billion gigabytes of text, while GPT-2 was trained on 40. While just increasing the scale in this way was not in itself novel, the new model’s ability to perform few-shot learning was a novel discovery, and was demonstrated in the paper via a variery of traditional Natural Language Processing tasks:



Following the release of the paper, it was announced on June 11 that GPT-3 will be usable by third-party developers through OpenAI’s API, which is the company’s first commercial product and is in closed beta.6 Access to GPT-3’s API “is invitation only, and pricing is undecided.” After the release of the API, multiple impressive demonstrations of GPT-3’s potential uses (in addition to writing short articles, blog posts, and creative fiction text generation) led to a flood of discussions within the AI community and beyond. One of the most noted examples the demonstration that it could be made to generate functional JavaScript code given a normal english description of the result:
This is mind blowing.
— Sharif Shameem (@sharifshameem) July 13, 2020
With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
W H A T pic.twitter.com/w8JkrZO4lk
Many similar demonstrations on Twitter soon followed:
Words → website ✨
— Jordan Singer (@jsngr) July 25, 2020
A GPT-3 × Figma plugin that takes a URL and a description to mock up a website for you. pic.twitter.com/UsJz0ClGA7
After many hours of retraining my brain to operate in this "priming" approach, I also now have a sick GPT-3 demo: English to LaTeX equations! I'm simultaneously impressed by its coherence and amused by its brittleness -- watch me test the fundamental theorem of calculus.
— Shreya Shankar (@sh_reya) July 19, 2020
cc @gdb pic.twitter.com/0dujGOKaYM
Since getting academic access, I’ve been thinking about GPT-3’s applications to grounded language understanding — e.g. for robotics and other embodied agents.
— Siddharth Karamcheti (@siddkaramcheti) July 23, 2020
In doing so, I came up with a new demo:
Objects to Affordances: “what can I do with an object?”
cc @gdb pic.twitter.com/ptRXmy197P
Which then inspired a large amount of discussion and interest.
The Reactions
The press, experts in the field, and the general tech community had widely differing opinions on both GPT-3’s capabilities and its potential implications when extensively adapted. Responses have ranged from heralding the future of human productivity and fear over losing jobs to more measured consideration of GPT-3’s capabilities and limitations.
Coverage from the press has increased since the demos came out:
- The MIT Technology Review provided sources that display the various ways GPT-3 can generate human-like text, from generating React code to writing poetry, while saying it “can generate amazing human-like text on demand but won't bring us closer to true intelligence.”
- The Verge focused on the potential commercial applications of GPT-3.
- In the wake of discussions on the topic, news sources such as Forbes and VentureBeat considered issues such as model bias and hype in their coverage of GPT-3.
- In addition to noting its imperfections, Wired pointed out that GPT-3 could introduce an even scarier version of deepfake technology, generating media for which there is no unaltered original to compare it to or to fact-check against. Synthetic text in particular can be produced easily at large scale and has fewer tells to allow for detection.
- Similarly, an opinion piece from New York Times columnist Farhad Manjoo titled “The new frontier in AI is amazing, promising ... and a little scary.” ponders the possibility of GPT-3 replacing the author and likewise covers reasons for concern.
- Lastly, John Naughton, professor of the public understanding of technology at the Open University, writing for The Guardian, sees GPT-3 as merely “an incremental improvement on its predecessors rather than a dramatic conceptual breakthrough.” Naughton warns that if such incremental improvements in technology are to be driven by applying more and more compute, the environmental costs will be enormous.
Compared to some of the press, reactions from experts in machine learning and NLP are largely more tempered and driven by curiosity, focusing on issues with how GPT-3 will be deployed and questioning its ability to truly understand language.
- Yoav Goldberg, NLP professor at Bar-Ilan University in Israel and
research scientist at the Allen Institute for Artificial
Intelligence reported
results
from GPT-3 on linguistically interesting prompts. With
one-line descriptions of tasks, Goldberg found some impressive
results. For instance, GPT-3 successfully wrote the plural forms of
words in a sentence completion task.These
were both novel words like “wug” and words with irregular plural
forms in English like “men.” He also noted how GPT-3 converted
statements to the passive voice and
questions,
and even produced answers to basic Python programming questions.
However, there are cases where GPT-3 falls short. One such prompt is
“what do dolphins and eagles have in common?” and GPT-3 responds,
“Both are birds.” Goldberg also prompts the model with a description
of a scene,
and it fails to answer certain questions accurately. These are both
examples of cases where it is trivial to answer these questions
using programs written from rule-based models, but GPT-3 fails to
provide a correct answer.
Following several conversations, I want to clarify:
— (((ل()(ل() 'yoav)))) (@yoavgo) July 18, 2020
I am amazed by its ability to learn various patterns of operation from 1-3 examples and carry them correctly. This is new and *super* exciting.
It does not "master all language" or "understands text".
It is not sentient. https://t.co/WEkxxkVIJm -
Anima Anandkumar, director of AI research at NVIDIA and professor of computing and mathematical sciences at Caltech critiqued the OpenAI team for not paying significant attention to bias in the model, especially considering that GPT-2 exhibited similar issues. This was because it was trained on data from unmoderated sources like Reddit, and thus would “learn” biases that are evident in texts written by humans (although it seems that the model can be primed to reduce gender bias).
- Jerome Pesenti, head of AI at Facebook, shared similar concerns:
#gpt3 is surprising and creative but it’s also unsafe due to harmful biases. Prompted to write tweets from one word - Jews, black, women, holocaust - it came up with these (https://t.co/G5POcerE1h). We need more progress on #ResponsibleAI before putting NLG models in production. pic.twitter.com/FAscgUr5Hh
— Jerome Pesenti (@an_open_mind) July 18, 2020
- Delip Rao, a machine learning researcher and entrepreneur, responded to all the discussion with the blog post “GPT-3 and A Typology of Hype,” which reflects on buzz about GPT-3 and how to determine which opinions about the technology contribute to or detract from hype and misinformation, given not only the author’s experience and engagement with technology, but also their desire to seek attention:
“GPT-3 and the buzz behind it is the beginning of the transition of few-shot learning technology from research to actionable products. But every breakthrough technology comes with a lot of social media buzz that can delude our thinking about the capabilities of such technologies.”
- Julian Togelius, an AI professor at NYU, likewise reflected on the excitement with his blog post “A very short history of some times we solved AI,” which noted that GPT-3 really is a breakthrough, but also reasons to temper the hype based on historical context:
“Algorithms for search, optimization, and learning that were once causing headlines about how humanity was about to be overtaken by machines are now powering our productivity software. And games, phone apps, and cars. Now that the technology works reliably, it's no longer AI (it's also a bit boring).”
- Dailynous, a site with “news for and about the philosophy professions”, hosted nine more reflections on GPT-3 from a variety of professors.
Commentators from the tech industry had mixed reactions, and some described the implications a “code-writing AI” would have on the labor market.
- Max Woolf, data scientist at BuzzFeed, stressed the importance of “tempering expectations” when it comes to evaluating GPT-3. This is because many of the examples of “intelligence” that are reported about are often cherry-picked, although the average quality of the generated text is better than that of other language models. Moreover, due to the fact that the model itself is extremely slow, large, and is trained on a vast amount of data, fine-tuning it to work with proprietary data would be highly unlikely.
- Kevin Lacker, former Google engineer and founder of the startup Parse, demonstrated that GPT-3 is able to give accurate answers to many questions asking about real-world facts, which can easily be learned from its training corpus. However, the model fails to correctly answer logical reasoning questions that would be trivial for humans. Blogger Gwern Branwen likewise evaluated GPT-3 on many tasks and with many contexts.
- In response to GPT-3’s ability to output code according to human specifications, Brett Goldstein, tech entrepreneur and former product manager at Google, claimed that, “Entry-level software engineering will be hit hard. The same will be true for design...Many companies will opt to use GPT-3 rather than hire expensive [machine learning] engineers to train their own (less powerful) models. Data scientists, customer support agents, legal assistants, and many more jobs are at serious risk.”
- In response to the many demos showing off GPT-3’s capabilities, Reddit user u/rueracine started a discussion about career paths in a post GPT-3 world. The user’s post indicates that there are at least some who take GPT-3 to be a signal that their jobs will no longer exist a decade from now. While some users are aggressively pursuing early retirement and urging the user to develop new skills in response to changing conditions. While some share the user’s concerns and see GPT-3 as significant progress toward “Artificial General Intelligence,” others believe such dire predictions are based on overestimating GPT-3’s capabilities.
- Educator in UX design Jonathan Lee likewise addressed some peoples’ concerns with his piece “Let’s talk about that GPT-3 AI tweet that shook designers to the core”, ultimately commenting people should be less worried:
“So, as we now consider the automation of the craft itself, AI will expedite our workflow in a way where some of that grunt work will no longer bury us in tedium. This will allow for more creative exploration and imaginative thinking — freeing us to discover new design paradigms. In the case of AI, it’s a matter of harnessing it.”
Sam Altman, CEO of OpenAI, responded to the widespread hype around the model by noting that although it certainly indicates progress in AI, there is still much ground to cover.
The GPT-3 hype is way too much. It’s impressive (thanks for the nice compliments!) but it still has serious weaknesses and sometimes makes very silly mistakes. AI is going to change the world, but GPT-3 is just a very early glimpse. We have a lot still to figure out.
— Sam Altman (@sama) July 19, 2020
In summary, many experts demonstrate interesting examples of what seems like linguistic comprehension with GPT-3. The press and tech community both applaud the progress of OpenAI’s work while cautioning that it could lead to massive technological upheavals in the future. However, the CEO of OpenAI agrees with researchers and other tech commentators that although GPT-3 represents immense progress in AI, it does not truly understand language, and that there are serious issues with using the model in the real world, such as bias and training time.
The Limitations
The impressive few-shot learning capabilities of GPT-3 represent a significant advance in AI, and the fact that it was achieved just by scaling up existing approaches was a useful discovery. Still, impressive demonstrations of its capabilities have generated an extraordinarily large amount of hype. Here, we will point out reasons that this hype may need to be tempered. In particular, GPT-3’s ability to perform tasks across many domains has re-introduced worries over AI and job loss--for example, the statement that GPT-3 might not only “replace coders, but entire industries” illustrates the concern. While GPT-3 certainly represents substantial progress for language models, it does not boast true “intelligence” or threaten to completely replace workers.
After all, GPT-3’s core model and training procedure is the same as many previous transformer-based models. Although scaling up has conferred significant performance improvements, GPT-3 retains the following limitations inherent to this architecture and training procedure:
- lack of long-term memory (as used currently, GPT-3 won’t learn anything over successive interactions, unlike humans)
- limited input size (for GPT-3, example “prompts” for the model can only be a few sentences in length)
- can only work with text (so, GPT-3 cannot reason about images, sound, or anything else humans easily can)
- lack of reliability (GPT-3 is opaque, so there is no guarantee it won’t generate incorrect or problematic outputs in response to certain inputs)
- lack of interpretability (when GPT-3 works in surprising ways, it may be hard to debug it to prevent similar situations in the future)
- slow inference (the authors note that models at the scale of GPT-3 are both expensive and inconvenient to perform inference on).
The last three points, and as well as other more technical ones, are in fact noted in the GPT-3 paper’s “Limitations” section.
Although technology similar to GPT-3 has the potential to change the nature of many professions, it does not necessarily mean that those professions will disappear. For one, as we have covered, adoption of new technologies is generally a slow and long process and many AI technologies complement rather than replace human workers. The former is even more likely to be the case, because the model is not perfect. Looking at the example of web development, someone who understands the technical details of the field will still be needed to correct and refine GPT-3’s code.
Computer vision, which had many “breakthrough” moments prior to NLP, created similar panics, like how AI would get rid of certain healthcare professions. However, instead of outright replacing doctors like radiologists, AI would be integrated into their workflow. Stanford radiologist Curtis Langlotz aptly noted, “AI won’t replace radiologists, but radiologists who use AI will replace radiologists who don’t.” A similar trend may persist for GPT-3; at the end of the day it is a model, and models are not perfect.
Beyond these pragmatic considerations, there are also theoretical ones. Before transformers were widely used for NLP, state-of-the-art results were achieved by bidirectional recurrent neural networks7 – which incorporate more words in the sentence when predicting a word’s probability under the model. GPT-3 on the other hand, is able to encode much fewer words in context than its recurrent predecessors.8 A paper by Ke Tran, Christof Monz (University of Amsterdam), and Arianna Bisazza (Leiden University) notes that transformers are much worse at modeling hierarchical structure in natural language when compared to recurrent networks. This is important, because a language’s syntax is described in terms of a hierarchy – words combine to make phrases, which combine to make more complex phrases and sentences. Even if transformers still perform effectively, having some learned notion of hierarchical structure is critical when it comes to developing a holistic model of language. While these issues can be mitigated with further research, they are worth noting in assessing the capabilities of GPT-3.
Some have commented that GPT-3 represents a significant step for AI towards “Artificial General Intelligence,” akin to what humans have. While certainly representative of progress, it is worthwhile to discuss a counterpoint to this sort of hype. Computational linguists Emily Bender (University of Washington) and Alexander Koller (Saarland University) recently proposed a thought experiment called the Octopus Test. In the experiment, two people are living on remote islands and communicate through a cable under the ocean, where an octopus is able to listen in on their conversations, acting as a proxy for language models like GPT-3. Eventually, if the octopus can successfully impersonate one of the people, then it “passes the test.” However, Bender and Koller propose several scenarios in which the octopus will be unable to successfully impersonate a person, such as building tools and self-defense. This is because the models only interface with text, and they have no conception of the real-world grounding that is critical to linguistic understanding.
Improving GPT-3 and its successors would be analogous to making the octopus “better at what it does.” As models like GPT-3 get more sophisticated, they will demonstrate different strengths and weaknesses; but learning only from written text is merely an exercise in reproduction: true “knowledge” or “understanding” comes from the interaction between language, the mind, and the real world, something a model like GPT-3 cannot experience.
In summary, GPT-3 is impressive but also fundamentally limited in many ways. Although it shows how NLP can change the nature of certain professions, GPT-3 is not a suitable replacement for humans in these roles due to its limitations. Additionally, it maintains many of the same theoretical limitations of the transformer architecture, failing to effectively model hierarchical structures and bidirectional contexts. The development of GPT-3 comes as the field of NLP discusses both the distinctions between form and meaning and considers alternative methods of evaluating language models, showing that the largest, most sophisticated models still have a long way to go when it comes to truly understanding natural language.
Conclusion
GPT-3 deserves acclaim for pushing the state of the art of language models and demonstrating what current techniques are capable of. But, we must not leap to conclusions about its far-reaching impacts on jobs and industries, and we must be aware of all the limitations in the model that still need to be addressed.
-
When a learning algorithm or model has more parameters, it is able to represent more complicated relationships from data than it would be able to otherwise. In the context of GPT-3, this means that it can memorize, or infer relationships between, pieces of information on the internet. ↩
-
GPT-3 being the largest language model to date refers to the fact that the model has a large number of parameters--the more parameters a model has, the more complex the data it can learn from. Large numbers of parameters are a key aspect of successful deep learning models. ↩
-
A language model is trained to predict the next word in a text, given preceding context. ↩
-
GPT-2 and GPT-3 are based on the transformer, a novel architecture that has been responsible for many recent advances in NLP. For a discussion of GPT-2 and GPT-3’s architecture, see this post. For a general introduction to Transformers, see this lecture. ↩
-
Text from the Internet, including Wikipedia, and data from books digitally available ↩
-
OpenAI is conducting a private beta with users that are individually vetted in order to decrease chances of misuse. According to their API blog post, OpenAI “will terminate API access for use-cases that cause physical or mental harm to people.” ↩
-
Recurrent neural networks were the first type of neural language model. They are particularly useful for modeling sequential data like sentences because they encode previous information while predicting the current state. This makes them especially effective compared to previously used statistical language models which are primarily count-based. Bidirectional RNNs achieve better results because they incorporate information about the entire sentence, not just a word’s preceding context. ↩
-
Attention is a method used by transformers, mentioned here. For a fairly technical introduction to bidirectional recurrent neural networks, see here. ↩





