AlphaGo Zero Is Not A Sign of Imminent Human-Level AI

AlphaGo Zero Is Not A Sign of Imminent Human-Level AI
Why DeepMind's Go playing program is not about to solve all of AI
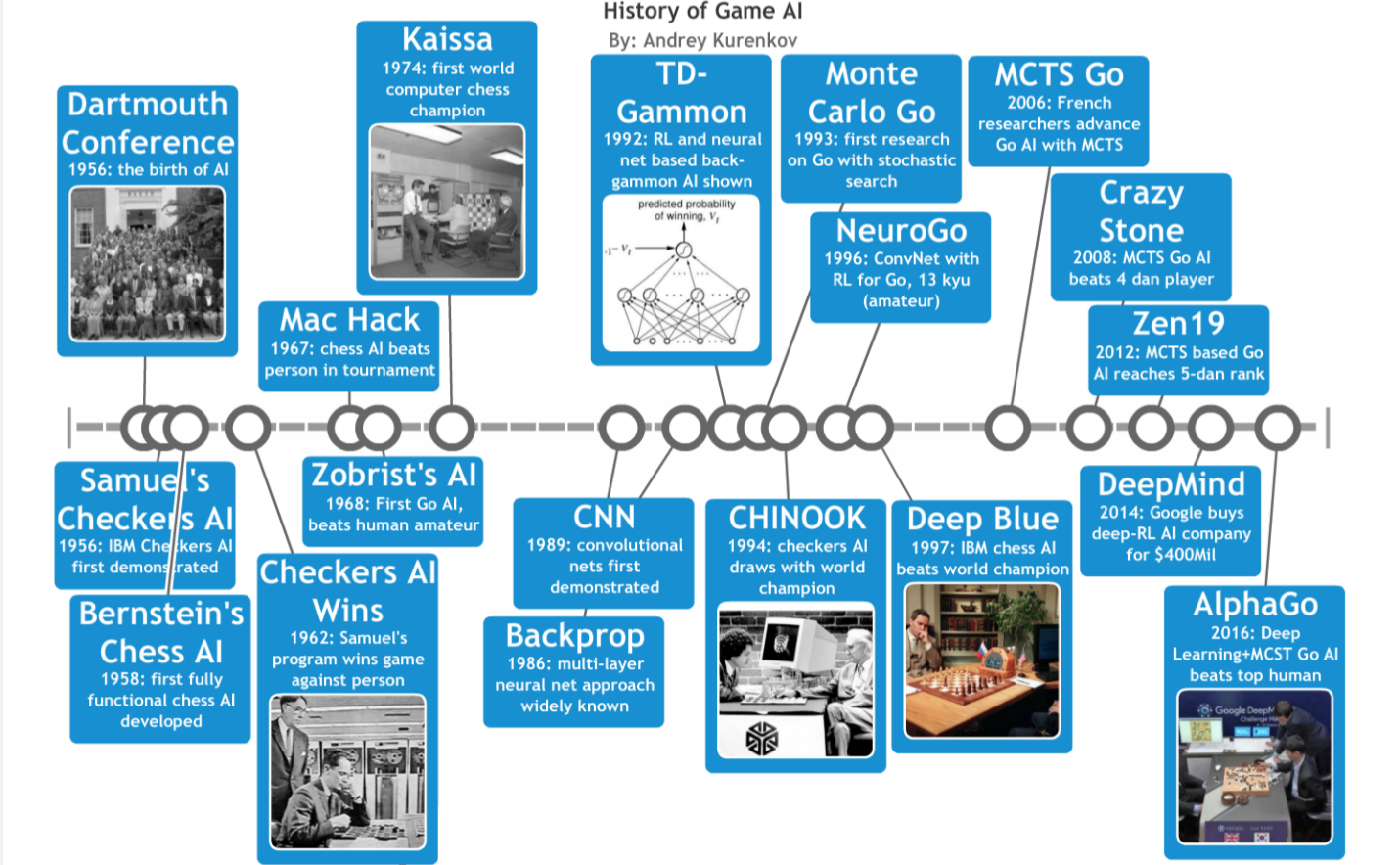
Why AlphaGo Zero Is Great
Let’s start with the coverage about DeepMind’s recent successor to AlphaGo1, AlphaGo Zero:
- “Google’s New AlphaGo Breakthrough Could Take Algorithms Where No Humans Have Gone”:
“While it sounds like some sort of soda, AlphaGo Zero may represent as much of a breakthrough as its predecessor, since it could presage the development of algorithms with skills that humans do not have. … AlphaGo achieved its dominance in the game of Go by studying the moves of human experts and by playing against itself—a technique known as reinforcement learning. AlphaGo Zero, meanwhile, trained itself entirely through reinforcement learning. And, despite starting with no tactical guidance or information beyond the rules of the game, the newer algorithm managed to beat the older AlphaGo by 100 games to zero.”
- “DeepMind’s Go-playing AI doesn’t need human help to beat us anymore”:
“The company’s latest AlphaGo AI learned superhuman skills by playing itself over and over”
- “‘It’s able to create knowledge itself’: Google unveils AI that learns on its own”:
“In a major breakthrough for artificial intelligence, AlphaGo Zero took just three days to master the ancient Chinese board game of Go … with no human help”
- ” Google Artificial Intelligence ‘Alpha Go Zero’ Just Pressed Reset On How To Learn”:
“Alpha Go Zero is changing the game for how we solve big problems.”
Point being: AlphaGo Zero (which we’ll go ahead and shorten to AG0) is arguably the most impressive and definitely the most praised2 recent AI accomplishment3. Roughly speaking, AG0 is just a Deep Neural Network that takes the current state of a Go board as input, and outputs a Go move. Not only is this much simpler than the original AlphaGo4, but it is also trained purely through self-play (pitting different AlphaGo Zero neural nets against each other; the original AlphaGo was ‘warmed up’ by training to mimic human expert Go players). It’s not exactly right that it learns ‘with no human help’, since the very rules of Go are hand-coded by humans rather than learned by AlphaGo, but the basic idea that it learns through self-play rather without any mimicry of human Go players is correct. I’ll let the key researcher behind it expand on that:
So, surely DeepMind’s demonstration that an AI algorithm can achieve superhuman Go and Chess play purely through self-play is a testament to the usefulness of such techniques for solving the hard problems of AI? Well, to some extent yes — it has taken the field decades to get here, since the branching factor of Go does indeed make it a challenging board game. This is also the first a time the same Deep Learning algorithm was used to crack both Chess and Go5, and was not specifically tailored for it such as was the case with Deep Blue (the much heralded machine of IBM that was the first to beat humanity’s best at Chess) and the original AlphaGo. Therefore, AG0 is certainly monumental and exciting work (and great PR).
Why AlphaGo Zero Is Not That Great
With those positive things having been said, some perspective: AG0 is not really a testament to the usefulness of such techniques for solving the hard problems of AI. You see, Go is only hard within the context of the simplest category of AI problems. That is, it is in the category of problems with every property that makes a learning task easy: it is deterministic, discrete, static, fully observable, fully-known, single-agent, episodic, cheap and easy to simulate, easy to score… Literally the only challenging aspect of Go is its huge branching factor. Predictions that AGI (Artificial General Intelligence) is imminent based only on AlphaGo’s success can be safely dismissed — the real world is vastly more complex than a simple game like Go. Even fairly similar problems that have most but not all of the properties that make a learning task easy, such as the strategic video game DotA II, are far beyond our grasp right now.

Another important thing to understand beyond the categorical simplicity of Go is its narrowness. AG0 is a definite example of Weak AI, also known as narrow AI. Weak AI agents are characterized by only being able to perform one ‘narrow’ task, such as playing a 19 by 19 game of Go. Though AG0 has the impressive ability to learn to play 3 different board games, it does so separately per game 6. And, it can only learn a vary narrow range of games: basically just 2-player grid based board games without any necessary memorization of prior positions or moves7.
"Generalized AI is worth thinking about because it stretches our imaginations and it gets us to think about our core values and issues of choice and free will that actually do have significant applications for specialized AI." - @BarackObama pic.twitter.com/VFhJsMXuIq
— Lex Fridman (@lexfridman) March 21, 2018
So, while AG0 works and its achievement is impressive, it is fundamentally similar to Deep Blue in being an expensive system engineered over many years with millions of dollars of investment purely for the task of playing a game — nothing else. Though Deep Blue was great PR for IBM, all that work and investment is not usually seen as having contributed much to the progress of broader AI research, having been ultra-specific to solving the problem of playing Chess. Just as with the algorithms that power AG0, human-tweaked heuristics and sheer computational brute force can definitely be used to solve some challenging problems — but they ultimately did not get us far beyond Chess, not even to Go. We should ask ourselves: can the techniques behind AG0 get us far beyond Go?
"Games (Chess, Go, Dota) represent closed systems, which means we humans filled the machine with a target, with rules. There is no automatic transfer of the knowledge that machines could accumulate in closed systems to open-ended systems." - Garry Kasparov pic.twitter.com/ysdV7sG9Qv
— Lex Fridman (@lexfridman) March 16, 2018
Probably, yes; the algorithms behind AG0 (Deep Learning and self-play) are inherently more general than human-defined heuristics and brute computation8. Still, it is important to understand and remember the parallels between Deep Blue and AG0: at the end of the day, both Deep Blue and AG0 are narrow AI programs that were built (at least in part) as PR boons for large companies by huge teams at the costs of millions of dollars; they deal with problems which are difficult for humans, but which are also relatively simple for computers.

I write this not to be controversial or take away from DeepMind’s fantastic work, but rather to fight against all the unwarranted hype AG0’s success has generated and encourage more conversation about the limitations of deep learning and self-play. More people need to step up and say this kind of stuff for the general public as well as the AI research community to not be led astray by hype and PR.
And all that aside, it should still be asked: might there be a better for AI agents to learn to play Go? The very name AlphaGo Zero is in reference to the idea that the model learns to play Go “from scratch”, without any further human input or explanation. But is learning ‘from scratch’ really such a good thing? Imagine you knew nothing about Go and decided to start learning it. You would definitely read the rules, some high level strategies, recall how you played similar games in the past, get some advice… right? And it indeed at least partially because of the learning ‘from scratch’ limitation of AlphaGo Zero that it is not truly impressive compared to human learning: like Deep Blue, it still relies on seeing orders of magnitude more Go games and planning for orders of magnitude more scenarios in any given game than any human ever does.
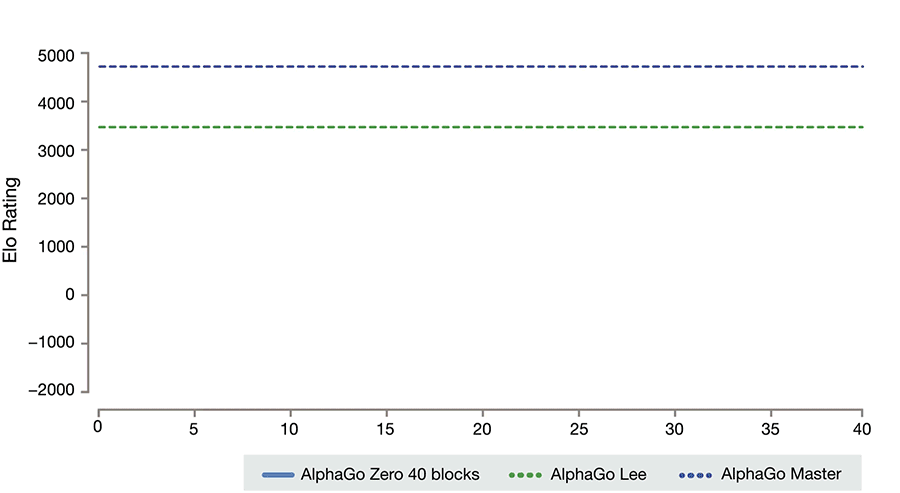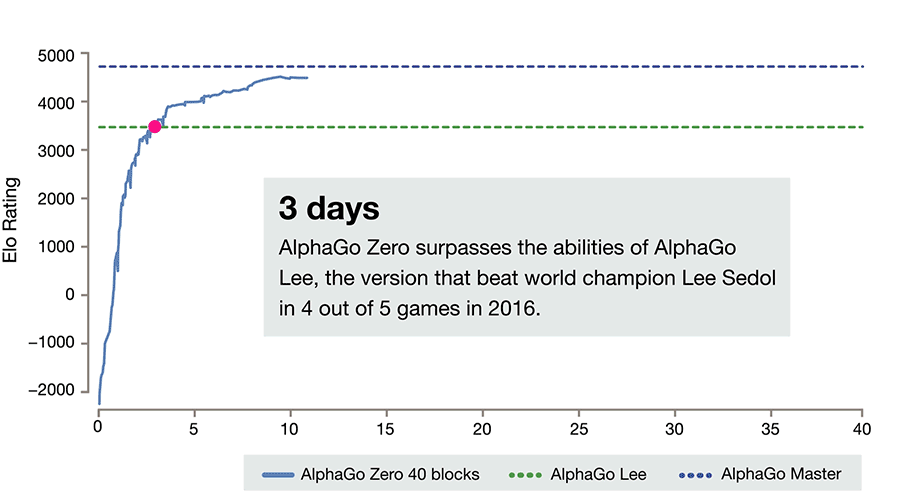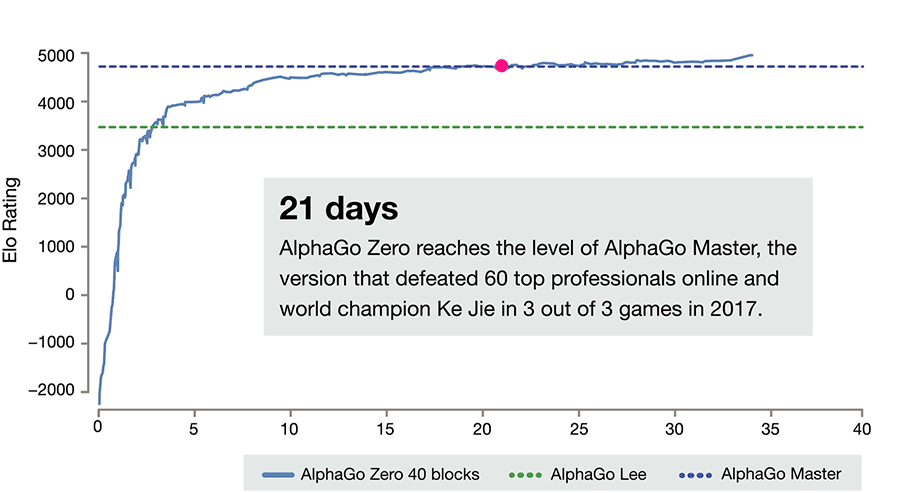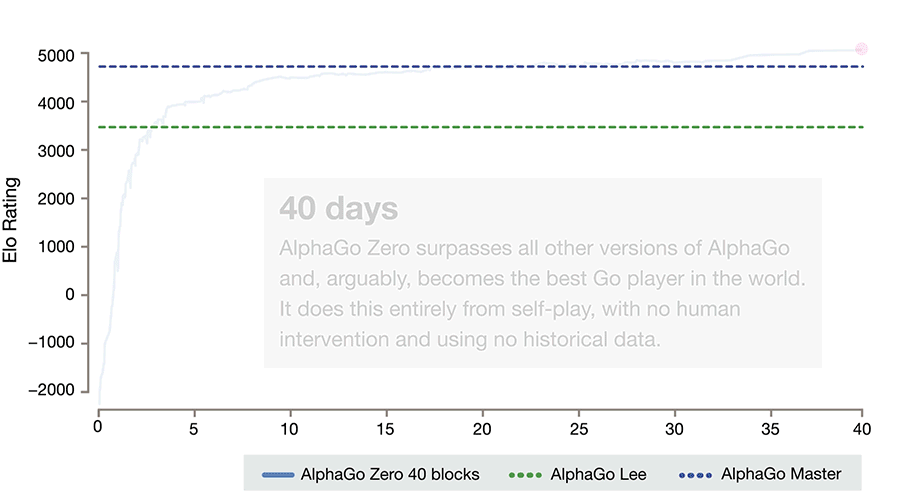
TLDR
So, let’s sum up: though AlphaGo and AG0’s achievements are historic and impressive, they also represent little if any progress in tackling the truly hard problems of AI (not to mention AGI). Still, as with any field all AI researchers stand on the shoulders of their predecessors; though these techniques may not foreshadow the coming of AGI, they are definitely part of the Deep Learning Revolution the field is still in the midst of and the ideas that they are based on will doubtlessly enable future progress. As with Deep Learning as a whole, it is important to appreciate these fantastic accomplishments for the field of AI without losing perspective about their limitations.
-
AlphaGo is the program that famously beat humanity’s best Go player Lee Sedol. ↩
-
At least, praised by non-technical news coverage ↩
-
For those unaware, AlphaGo Zero is the name of an algorithm discussed in a paper late last year. ↩
-
In contrast to AG0, AlphaGo involved several neural nets and features specific to Go. ↩
-
There are many approaches to General Game Playing that cover much more than just Chess and Go, and neither AG0 nor any Deep Learning approach had yet to be compared to those in the standard competitions they are pitted against each other at. ↩
-
That is, there is not a single trained neural net that can play the 3 games, but 3 separate neural nets with one for each game. ↩
-
That is, on any given move the board contains all the necessary information to decide on the next move; no memory of the past required. ↩
-
It’s quite likely that right now researchers and engineers at DeepMind are working hard to demonstrate the next version of AlphaGo, which will presumably learn to play multiple games rather than just one. ↩





