The singularity isn’t here yet. Biased AI is.

The singularity isn’t here yet. Biased AI is.
A summary of what AI bias is, why we should care, and what we can and are doing about it
Image credit: Medium
While we worry of the fictional Skynet appearing tomorrow, there are concrete elements of AI that should worry us today: machine learning algorithms, trained on often biased data and thus reinforcing that bias, are affecting people’s lives in the present. When was the last time you looked up a price of a car insurance, or tried to get a loan? Chances are, a multitude of data points were taken into account when offering you a price, particularly if you did so online. Elements such as the browser you were using, your geolocation or type of connection were probably all taken into account before offering you a price.
It wasn’t a person weighing all these different elements, or ‘features’, if you like, but a machine learning algorithm that was taking the ‘features’ characteristic to your search, and putting them into a model1. This model allows the insurance company or bank to compare your request to similar past transactions that were successful or less successful for their institutions.
Thus, for example, if chrome users were more likely to pay their loans back in time, chrome users of the future should be more trustworthy and thus get better prices or terms of use (in fact, Joe Deville found that even your screen resolution could matter). Taken at face value, that seems fair. Companies are trying to make use of all the data they have in order to form an idea of who is the customer they are dealing with. In some cases, that will also translate to better prices and benefit trustworthy users. It will of course affect others adversely, but after all, data doesn’t lie. They surely had it coming.
Unfortunately, this seemingly objective process might not be so objective after all. In a conference last year, John Giannandrea, head of Google’s AI efforts, claimed he was not worried about doomsday tales of killer robots, but much more concerned with AI fairness. “The real safety question”, claimed Giannandrea, “is that if we give these systems biased data, they will be biased”.
Machine learning algorithms rely on data, and are only as good, or fair, as the data they are trained with (‘garbage in, garbage out’, as the research community likes to say). If, for example, past data tells us that certain minority groups were less likely to receive loans or mortgages in the past, that should not necessarily be the benchmark we want for the future. What was does not have to be what will be. And in many cases, what was should not be what will be, since our notions of ethics evolve over time and there are limitless examples of beliefs and practices that were deemed fine in the past but we now seek to correct.
Questions of Allocation
It was not so long ago that AI algorithms developed by researchers started to be used for automation of decision making tasks in domains such as job hirings, the criminal justice system, the insurance industry, and many more. The theoretical benefits of deploying algorithms for the use of making decisions over people’s lives seemed promising. Besides just being plain faster and infinitely more scalable than people, algorithms also don’t see color, gender or anything at all except for what they are trained to look for. We could fight humanity’s most deeply ingrained biases and start over with a clean slate, so the argument went, with systems that could be, for once, truly objective.
But more and more examples started showing up where that wasn’t exactly the case. A 2016 report from ProPublica showed that systems used across the US to assign risk levels to criminals – reflecting their likelihood to reoffend and thus affect their treatment by the judicial system – might be biased against people of darker skin color. This report has been challenged since, and yet remains a reminder of the effects of decision making algorithms when they are not carefully designed with potential bias in mind.
There’s some evidence to show that these algorithms, which often operate behind the scenes and without the knowledge of consumers, start to replicate worrying patterns from the past.
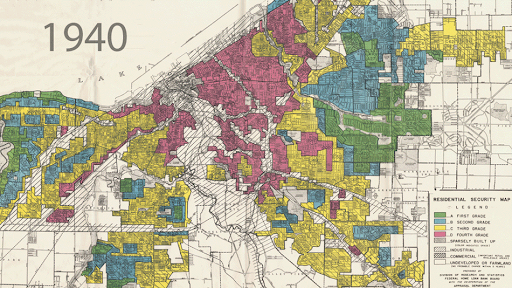
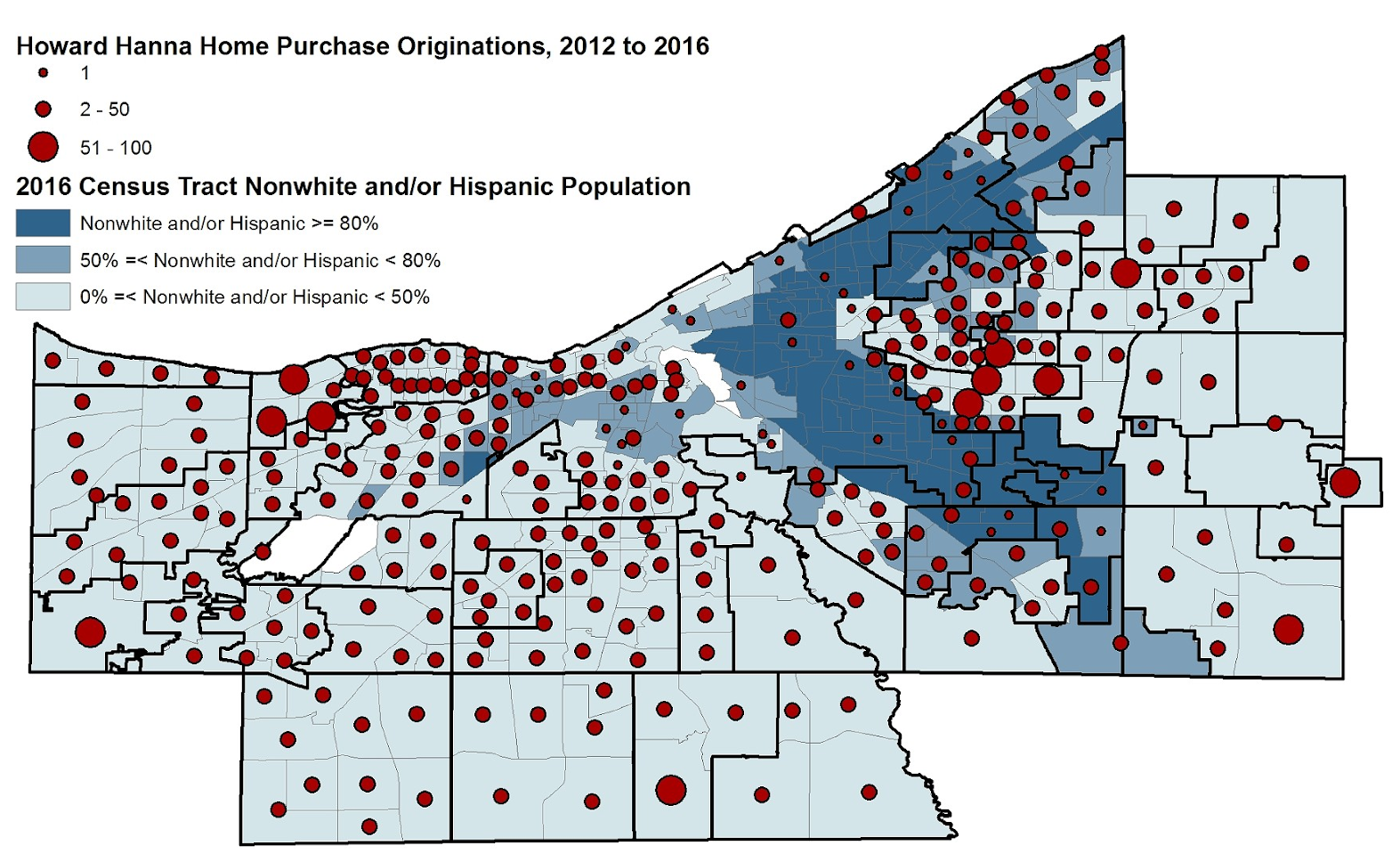
In the 1930s US, it was common for mortgage to ‘redline’ disadvantaged communities, thus blocking them from getting access to mortgages. These redlined districts were predominantly black communities, and in the 1970s new regulation intervened and tried to fight this systematic discrimination. However, new studies done on the outcomes of new algorithmic credit scoring systems, which are involved with making similar decisions about mortgage and loan granting, show similar worrying patterns. Furthermore, this time around scoring algorithms are operating in a hidden fashion, often without any explanation given. A similar segregated map emerged in 2016 when comparing Amazon Prime’s same-day delivery service, which back then excluded predominantly black neighborhoods in numerous metropolitan areas across the US (after publication of this fact in a Bloomberg report, Amazon changed its policy).
Old vs. New
Human history is not objective, because it is written by people. And machine learning algorithms are little more than statistical models that are particularly good at spotting patterns in historical data to form predictions about the future. They learn from previous data which are created by, fed by, and selected by humans. Thus, rather than operating ‘objectivity’, they can instead encode bias; they are only as objective as we train them to be, and only as ethical as their creators care to make them.
Biased data giving rise to biased models is by no means only an American problem. Police forces in the UK have also started deploying risk assessment algorithms recently and led to a troubled report by RUSI, a UK based leading think tank in the field of defence and security.
Amazon was reported to have shut down a new automated hiring tool, at least partially because it discriminated against female candidates. Cathy O’Neil, a former data scientist who quit a lucrative job as a designer of similar systems, details in her excellent Weapons of Math Destruction how algorithms can contribute and exacerbate inequality, as they are deployed in business sectors as different as online advertising, the judicial systems, hiring processes, loans provision, education admissions and more. And the list goes on.
The same problem seems to creep up in so many fields of application, it has led the researchers Kate Crawford and Ryan Calo to classify it as a blind spot of AI research. AI bias, they claimed in an opinion piece in the scientific journal Nature, is a big enough of a concern to prompt the formation of a new field of study and employment: social-systems analyses of AI.
The examples explored to this point can all be classified under discrimination of allocation. They all harm their victims by blocking their access to resources or restricting them in some other way. However, algorithms can also inflict a more subtle form of harm, which we will explore next.
A crisis of representation
Decision making algorithms are mostly hidden for now, working behind the scenes and often without the affected side being aware of it. Those who could be affected most severely are also those who are the farthest away from the development of the technology. A lack of representation in the design process, we are learning, often means a lack of representation in datasets, and eventually in outputs of algorithms. A discrimination of representation, if you will.
Joy Buolamwini, as a PhD student at MIT, showed that multiple commercial facial recognition softwares failed to recognize her; she had to wear a white mask for the system to be able to identify her. The model was not designed to be worse at dealing with her dark skin tone, but as covered previously on Skynet Today, it just wasn’t trained on relevant data that could help it recognize Buolamwini either.
A similar finding was recently covered here on Skynet Today, concerning the worrying degree to which a model trained by a product from Amazon identified African American senators to be convicted felons more often than their white colleagues. While Amazon rightfully argued that these results were obtained while not using their recommended error margin, there are also reasons to believe they did not communicate these best practices effectively to their clients before the publication of the piece that pointed that phenomenon out. Either way, the difficulty existing systems experience when being confronted with certain minority groups is evident.

Another underrepresented group in the machine learning community is women, and it too has discovered a problematic representation in a commonly used machine learning tool. Word embeddings are representations of the proximity of association of words within big corpus of text.
The two most popular pre-trained word embeddings are Word2Vec and GloVe, trained on millions of wikipedia, google news articles and the like. And since they process language as it naturally occurs on the internet, they also show signs of gender bias as it occurs on the internet. Male names appear in much greater proximity to business and scientific professions, while female names in these models appear closer to teaching professions or simply homemaking related words.

And if you find this representational problem too abstract, know that google translate behaves similarly when asked to translate texts from non-gendered languages, back into gendered ones. For example, when translating a poem from Turkish, where less gender pronouns exist, google translate decides to translate the same word as ‘he’ in a sentence describing a hard worker, but ‘she’ when describing a lazy person.
Turkish is a gender neutral language. There is no "he" or "she" - everything is just "o". But look what happens when Google translates to English. Thread: pic.twitter.com/mIWjP4E6xw
— Alex Shams (@seyyedreza) November 27, 2017
And this subtle form of discrimination also rears its head in the systems that target us with ads online. Latanya Sweeney of Harvard University famously showed that searches for predominantly black names prompt ads suggestive of arrest records, while predominantly white names do so far less often. Similarly, women were shown to be less targeted by ads for high-paying executive jobs than equivalent male searchers.
There are many more examples. For example, Google’s speech recognition was shown to perform better on male voices than female voices back in 2016. There was the time the image recognition software in google photos tagged black men as gorillas back in 2015. Although this unfortunate blunder was fixed, there was some discussion about the quality of that fix. Unfortunately, it is very likely that new examples will continue coming about.
Although it might be tempting to dismiss this type of more hidden discrimination, it is ethically and practically wrong. It is a question not just of representation in existing systems, but also of the further implications these systems will have on future products that will rely on them. Thus, a hiring process that relies on word embeddings could discriminate against women, and facial recognition systems that do worse on faces of a minority group could not be as reliable when used in law enforcement or other systems.
The machine learning community was historically not focused on questions of social impact, ethics, and due process. It is also a small community but one with a big and growing impact, and not known for its remarkable diversity. However, in an age where this community is building systems that affect society at large, questions of diversity of representation are becoming increasingly important. Fortunately, as we will discuss soon, this realization is already increasingly popular in the AI research circles.
Communication breakdown: black boxes and silent algorithms
Machine learning algorithms are focused on minimizing error, and during their development researchers were less worried about informative explanations of algorithmic decisions than they were about beating benchmarks, of either previous algorithms or the equivalent human capacities, and rightfully so. However, as those same algorithms now operate in closer proximity to society at large, the plot thickens.
Many models currently do not offer explanations to accompany their outputs. Thus, when a risk assessment algorithm spits out a score for an individual, we do not know exactly which elements about the individual in question influenced the decision. Similarly, we do not know what makes a system prefer one candidate over another in a semi-automated hiring process, both because the model is often a ‘black box’ that doesn’t provide a clear explanation, and because the model might be shielded by proprietary algorithm protections.
The idea of 'black box' algorithms is increasingly present in the conversation about #Facebook #FacebookDataBreach. Here's a graphic I made to describe a #blackbox in the simplest of terms. Algorithms, the more complex they are, are also more difficult to understand. pic.twitter.com/0JPT9qMEFk
— Kourosh Houshmand (@Kourosh_Housh) March 22, 2018
And while traditional biases or unfairness was highly imperfectly held accountable through due process, algorithms are as a hidden beaurocrat as can be, and one that, in its present iteration, provides very little explanations. This basic communication difficulty makes issues of due process, complaint or legal action much trickier.
The scale of the challenge
It is important to note that fairness is an already controversial topic humans have a hard time agreeing on, even before machines entered the arena. For example, in the case of university admissions, we could aim to ignore race or any correlated feature to it as input to an algorithm. But that would not allow for affirmative action2. Even worse, it could fail to recognize the unique characteristics applicants from underrepresented communities share (as explained by Cynthia Dwork).
Even when considering the ProPublica report on possible bias against African Americans of risk assessment algorithms in the America judicial system, our standards of measurements of fairness will define whether bias exists or not. As explained here by Krishna Gummadi of the Max Planck Institute for Software Systems, a criminal justice algorithm could aim to optimize ‘true positives’, meaning to assign a high risk to as many actual reoffenders as possible, even at the price of a high risk score for individuals who will not reoffend, or ‘false positives’.
However, ProPublica chose to focus on the number of ‘false negatives’, those who were assigned high risk scores who subsequently weren’t involved in future criminal activity. Reducing these ‘false negatives’ (that are statistically more significant in the case of black individuals than white individuals), could also mean assigning lower scores to individuals who will reoffend, and thus risking higher crime rates overall.
It has also been shown that there could be a fundamental tension between accuracy of a model and its simplicity for interpretation, and a further tension between interpretability and fairness. With our current models, it seems like the two axes are trade-offs we need to learn to balance and standardize across various applications: should we prioritize accuracy over interpretability in our criminal justice system? Should we prioritize fairness over ease of interpretation in higher education admissions? These are just as much political and social questions as they are technical ones.
In other words, fairness and bias are not only hard to monitor, they are often hard to define, and could be defined differently based on context or domain of application. AI fairness is thus likely to be a moving target we constantly aim for, rather than a stationary goal post we can fully achieve. It requires a whole suite of tools:
- a framework for the continuing fairness assessment and monitoring of systems, before and after deployment
- the right regulatory and legal language to promise individuals could indeed have a right for reasonable fairness, and the ability to protest algorithmic decisions that are not justified
- technological solutions to advance AI transparency, the ability of models to provide minimal explanations, and the development of diverse and bias-proof datasets, both as training matter for future systems, and as benchmarks against which we can measure newly developed models.
Given the diversity and scope of these challenges, it is not hard to see why Kate Crawford and Ryan Calo proposed the notion of a whole field for social-systems analysis.
The light at the end of the model
For all these possible hazards of decision making models, the solution should not be to throw our arms up in despair or ban them altogether. Just as it was wrong to insist on the automatic objectivity of models, so would it be flawed to condemn AI decision making all together. Machine Learning can and already has been used in ways that avoid unintended bias, and researchers are increasingly tackling the challenge of making that easier to do.
Carefully crafted algorithms helped, for example, replace the historic bail system in New Jersey that kept poor defendants who could not afford the cost of their release behind bars even when they were innocent. There is also some evidence to suggest that algorithms are better at hiring candidates for certain jobs than humans long trained to do so. Clearly, well designed systems could provide so many benefits, it is highly worthwhile investing efforts into getting them right.
Since 2016, the Machine Learning community has seen a surge in the interest of researchers in questions of AI fairness and transparency. As a result, more and more groups now focus on the problems surveyed above such as the AI NOW institute, Alan Turing Institute in London, Black in AI, and the Algorithmic Justice League. The study of AI fairness is also increasingly a multi-disciplinary effort. Social scientists and legal scholars are increasingly getting involved in the conversation: recently a ‘right for a reasonable inference’ framework was proposed by researchers at the Oxford Internet Institute.
These groups, as well as individual researches and corporations, have begun to address these problems with technical ideas, tools, datasets, and suggestions for new best practices:
- The same group that showed the gender bias phenomenon in word embeddings proposed a technical solution within the same paper. Researchers have also proposed an approach for fostering the development of systems that are more just, through technical solutions such as linear approaches, counterfactuals, and Seldonian optimization.
- More and more, key industry players acknowledge the problem and come up with services to improve machine fairness. IBM recently launched a cloud tool that could help detect AI bias and explain automated decisions, while Microsoft and Facebook already announced they are working on similar products.
- And as far as best practices, researchers at Google have suggested to start reporting standards of performance of models before they are released via ‘model cards’ (similar to datasheets supplied with many technical products) ), which could counteract unintentional bias by making it standard to explicitly evaluate whether it is there. IBM has also proposed the idea of fact sheets for fair AI system design which pose some fundamental questions to be checked during the development of new systems.
- As for diversity of data itself, Google has also created an inclusive image recognition challenge, partnering with Kaggle, the most popular platform for data science project competitions. IBM has also contributed a more inclusive facial image dataset.
A final positive trend is the increasing number of online resources with which it is possible to educate oneself about these topics. Ways to engage with the topic include the Fair ML book that is currently under development, Google’s new class on the subject, and fast.ai’s resource list.
Lingering questions
Although we are already moving in the direction of finding answers, there is still significant work to be done crafting the right questions. A common question in discussions of the topic of late is whether we can really expect a higher ethical standard of algorithms than we do of humans. There is of course no right answer to this question, but regardless of the answer one gives, it is definitely true that the sheer scale of a decision making model makes its outputs much more influential than that of any single human. Thus, machine decisions are just of a higher stake.
It is also not clear if we can quantify or formalize questions of ethics that many have spent years philosophising over to no avail. In fact, if society does not accept the ‘what was is what will be’ assumption, can algorithms help us at all in reaching fair and just decisions? The answer is not a binary one. We should not accept all past examples as ground truth, but no one is suggesting to get rid of history all together as an aid in reasoning.
If history is helpful, so are models trained on historical examples, so long as their underlying data and outputs are regularly checked and fine-tuned to promise that no past biases are automatically replicated and amplified. The question is not whether we can develop the perfect system, but whether we can do any better, and hopefully better yet thereafter.
The road for ever better algorithms is long, and might not have a finish line. But to keep on making progress the first step is to admit that there is a problem. Public awareness is key in expressing a demand for a fairer development and testing of systems that apply to all of us. So, there is a clear list of at least a few things we can and should work on now:
- We need to train more experts to study and answer some of the questions posed here, but also to involve ever more social groups in these discussions, and demand our lawmakers to step up and develop the right frameworks to ensure models are carefully crafted and maintained.
- We need scientists to give us the right tools, legal scholars to make sure we deploy them, and social scientists, or better yet social system analysts to regularly check the algorithmic decision making industry is towing the line.
- And more than ever, we need robust and inclusive discussions about what is fair, what we really want algorithms outputs to look like, and understand that while an evolving concept, machine fairness is crucial for the health of both the AI community and society at large going forward.
While we might never find absolute true answers or perfectly fair and just algorithms, we can aim to find answers that are better than the ones we have now. Through trial, error, research and awareness, we must aim to make our growingly computational societies more ethical and equitable.
-
“Model” is just a fancy term for some code that, given some set of input ‘features’, spits out some output, like a score or a yes/no decision ↩
-
the systematic preference of one group over another, within some constraints, in order to compensate for historical and systematic forms of discrimination that could have implicated a candidate from an underrepresented group ↩






{kind=link}