OpenAI’s GPT2 - Food to Media hype or Wake Up Call?


OpenAI’s GPT2 - Food to Media hype or Wake Up Call?
An effort to encourage the AI research community to talk about responsible disclosure of technology was met by strong criticism
Image credit: Delip Rao, When OpenAI tried to build more than a Language Model
What Happened
We've trained an unsupervised language model that can generate coherent paragraphs and perform rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training: https://t.co/sY30aQM7hU pic.twitter.com/360bGgoea3
— OpenAI (@OpenAI) February 14, 2019
On February 14 of 2019 the non-profit AI research company OpenAI released the blog post Better Language Models and Their Implications, which covered new research based on a scaled up version of their transformer-based language model 1 initially released in June 2018. The model, called GPT-2 2, was shown to be capable of writing long form coherent passages after being provided a short prompt. This is an impressive feat that previous models have struggled to do effectively but something that the field was moving towards.
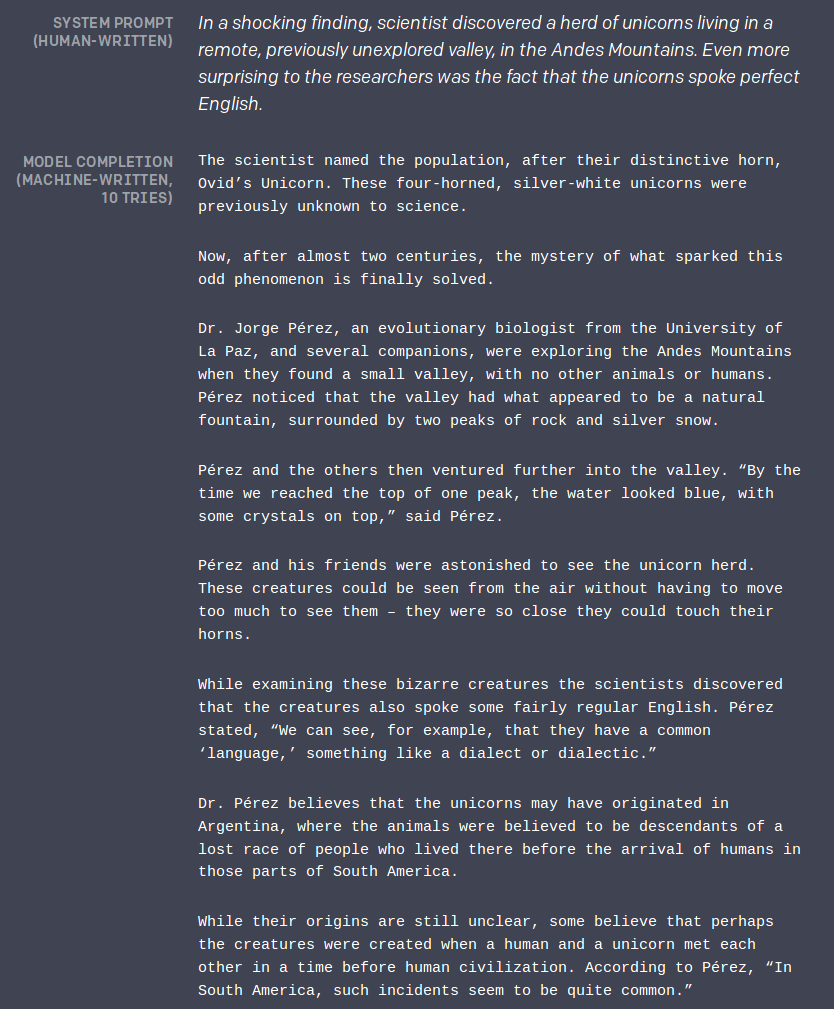
In addition to presenting these impressive new results, the post commented on several potential misuses of their state-of-the-art model (such as generating misleading news articles, impersonating others online, and large-scale production of spam) and explained that OpenAI chose to pursue an unusually closed release strategy because of these potential misuses:
“Due to concerns about large language models being used to generate deceptive, biased, or abusive language at scale, we are only releasing a much smaller version of GPT-2 along with sampling code. We are not releasing the dataset, training code, or GPT-2 model weights… This decision, as well as our discussion of it, is an experiment: while we are not sure that it is the right decision today, we believe that the AI community will eventually need to tackle the issue of publication norms in a thoughtful way in certain research areas. Other disciplines such as biotechnology and cybersecurity have long had active debates about responsible publication in cases with clear misuse potential, and we hope that our experiment will serve as a case study for more nuanced discussions of model and code release decisions in the AI community.”
This goes against what is increasingly the norm in AI research — when sharing new findings, it is now typical to also share data, code, and pre-trained models for running the relevant experiments. This has been one of the main reasons the field has progressed so rapidly over the past decade, as researchers don’t have to spend months reproducing each other’s work and can verify and build on new results quickly. Although this has been benefitial, many in the field have also started to discuss the potential of open source code and pre-trained models for dual-use 3 and the implications of that for how researchers should share new developments.
Such a coherent set of output, as well as OpenAI’s strong stance on not releasing their model, data, and code, were notable enough to turn much attention towards it. This alone would have been enough to incite much discussion, but there was a second element to this event: prior to the AI research community being aware of this new work, multiple journalists were informed of it and provided with access to write articles to be released soon after the blog post. The flurry of media coverage almost instantly made OpenAI’s blog post and coverage of it a huge source of discussion for the AI research community.
The Reactions
As is often the case, most reporting from reputable sources covered the details accurately. For example, from OpenAI’s new multitalented AI writes, translates, and slanders:
“…But as is usually the case with technological developments, these advances could also lead to potential harms. In a world where information warfare is increasingly prevalent and where nations deploy bots on social media in attempts to sway elections and sow discord, the idea of AI programs that spout unceasing but cogent nonsense is unsettling.
“For that reason, OpenAI is treading cautiously with the unveiling of GPT-2. Unlike most significant research milestones in AI, the lab won’t be sharing the dataset it used for training the algorithm or all of the code it runs on… ”
At the same time, most coverage went with eye-catching headlines that ranged from “New AI fake text generator may be too dangerous to release, say creators” to “Researchers, scared by their own work, hold back “deepfakes for text” AI”.
Hyped up results don’t make anybody happy. It hurts AI researchers by promoting fear mongering or setting unrealistic expectations, and the public by promoting incorrect understanding of their work. So finding out about new results in their field through such headlines prompted many in the AI research community to voice criticism of OpenAI’s arguably PR-first communication of research and the decision of not publicly releasing their models. Some lauded the move as a bold and necessary step towards responsible AI:
Going so far as to think ahead to malicious uses and check in with stakeholders sets a new bar for ethics in AI. Well played @openai, @jackclarkSF.
— Brandon Rohrer (@_brohrer_) February 15, 2019
I'd like to weigh in on the #GPT2 discussion. The decision not to release the trained model was carefully considered and important for norm-forming. Serving the public good requires us to draw lines on release somewhere: better long before catastrophe than after.
— Joshua Achiam (@jachiam0) February 17, 2019
Others considered it either a futile attempt or a poor decision doing more harm than good:
- Anima Anandkumar, Director of AI NVIDIA
What you are doing is opposite of open. It is unfortunate that you hype up +propagate fear + thwart reproducibility+scientific endeavor. There is active research from other groups in unsupervised language models. You hype it up like it has never been done before. @jackclarkSF
— Anima Anandkumar (@AnimaAnandkumar) February 15, 2019
- Zachary Lipton, Professor CMU
Perhaps what's *most remarkable* about the @OpenAI controversy is how *unremarkable* the technology is. Despite their outsize attention & budget, the research itself is perfectly ordinary—right in the main branch of deep learning NLP research https://t.co/bmMkkL3KKJ
— Zachary Lipton (@zacharylipton) February 17, 2019
- Denny Britz, former Google-Brain researcher
Also consider: OpenAI is worried about the model falling into the wrong hands. But instead of releasing code/paper for researchers and trying to keep it low-key they make a huge PR splash, telling every last spammer on the planet. The choices seem a little… incompatible?
— Denny Britz (@dennybritz) February 15, 2019
- Richard Socher, Principal Scientist, Salesforce Research
But their perplexity on wikitext-103 is 0.8 lower than previous sota. So it's dangerous now. 🙃
— Richard (@RichardSocher) February 14, 2019
In other news. Copy and pasting and Photoshop are existential threats to humanity.
PS: Love language models. Love multitask learning. Great work. Dislike the hype and fear mongering.
- Mark O Riedl, Professor at Georgia Tech
It’s a win-win-win for OpenAI. (1) It’s good work. (2) Not releasing the model artificially (and unnecessarily) inflates this perspective while simultaneously prohibiting replication. (3) Get to talk about saving the world by ramping up the fear of AI.
— Mark O. Riedl (@mark_riedl) February 14, 2019
Let’s also stop and reflect on how reporters knew about this work longer than other scientists. Some of them reached out to academic researchers for comment, but it’s a powerful way to take early control of the narrative surrounding the technology.
— Mark O. Riedl (@mark_riedl) February 15, 2019
- Francis Chollet, author of Keras, researcher at Google
We all want safe, responsible AI research. The first step is not misrepresenting the significance of your results to the public, not obfuscating your methods, & not spoon-feeding fear-mongering press releases to the media.
— François Chollet (@fchollet) February 18, 2019
That's our 1st responsibility.https://t.co/tqX07LbRit
- Matt Gardner, research scientist at AllenAI
Key word here: "humbly". I do not see what @OpenAI did as "humble" - going _first_ to a ton of news organizations with your findings as way to further scientific discourse is pretty much the opposite of that. That's the only thing I took issue with. The research is great.
— Matt Gardner (@nlpmattg) February 17, 2019
OpenAI’s reasoning was also openly satirized by many in the AI community:
- Yoav Goldberg, Professor at Bar Ilan University and Research Director of the Israeli branch of the Allen Institute for Artificial Intelligence
Just wanted to give you all a heads up, our lab found an amazing breakthrough in language understanding. but we also worry it may fall into the wrong hands. so we decided to scrap it and only publish the regular *ACL stuff instead. Big respect for the team for their great work.
— (((ل()(ل() 'yoav)))) (@yoavgo) February 15, 2019
- Yann LeCun, Chief AI Scientist at Facebook AI Research, Professor at NYU
<trolling-joking>
— Yann LeCun (@ylecun) February 19, 2019
Every new human can potentially be used to generate fake news, disseminate conspiracy theories, and influence people.
Should we stop making babies then?
</trolling-joking>
During this, Jack Clark and Miles Brundage at OpenAI were active in trying to provide answers, share the thought process, and take feedback on how they can improve things in the future.
I think there's a lot of stuff that we're gonna learn from this as we figure out future plans - as discussed in blog "this decision, as well as our discussion of it, is an experiment". We're also really excited to get feedback here and languagequestions@openai.com
— Jack Clark (@jackclarkSF) February 15, 2019
All good points. I think going forward we will be more transparent/proactive in our outreach to the rest of the AI community on this, and weight that more. At the time, it seemed like we had a few objectives to satisfy, inc. raising awareness of this broader class of systems...
— Miles Brundage (@Miles_Brundage) February 18, 2019
The conversation was prolonged enough for many follow up articles to be written going more into-depth on these topics:
- Some thoughts on zero-day threats in AI, and OpenAI’s GP2
- Should I Open-Source My Model?
- OpenAI Trains Language Model, Mass Hysteria Ensues
- An open and shut case on OpenAI
- OpenAI’s GPT-2: the model, the hype, and the controversy
- When OpenAI tried to build more than a Language Model
- OpenAI: Please Open Source Your Language Model
- OpenAI Shouldn’t Release Their Full Language Model
- Dissecting the Controversy around OpenAI’s New Language Model
- Humans Who Are Not Concentrating Are Not General Intelligences
- Who’s afraid of OpenAI’s big, bad text generator?
- OpenAI’s Recent Announcement: What Went Wrong, and How It Could Be Better
In summary, while most people agreed with the need for talking about the possible implications of the technology AI researchers are building, many criticized OpenAI’s tact for the following reasons:
-
Giving reporters early information and preferential access to cutting edge research shows a focus on PR over making research contributions.
-
The malicious uses of GPT2 were merely hypothesized, and OpenAI did not even make it possible for researchers in the field to request access to the model or data. Such practices may lead to the rise of gatekeeping and disincentivize transparency, reproducibility, and inclusivity in machine learning research.
-
Given the existence of similar models and open source code, the choice to not release the model seems likely to impact researchers and individuals not interested in large-scale malicious use. The cost for training the model was estimated to $43,000, an amount insignificant for malicious actors, and a number of clones of the dataset used have popped up since OpenAI’s announcement as well.
-
OpenAI did a poor job of acknowledging prior considerations about dual use in this space.
Our Perspective
Today's meta-Twitter summary for machine learning:
— Smerity (@Smerity) February 15, 2019
None of us have any consensus on what we're doing when it comes to responsible disclosure, dual use, or how to interact with the media.
This should be concerning for us all, in and out of the field.
There is not much left to be said on this story, and the series of tweets above as well as the articles Who’s afraid of OpenAI’s big, bad text generator? and OpenAI’s Recent Announcement: What Went Wrong, and How It Could Be Better cover what really needs to be said well. Even if OpenAI’s stated intentions were authentic (which is likely the case given the company’s prior focus on dual-use and stated focus on promoting practices that prevent misuse of AI technologies), a better thought out approach to communicating their new research and hypothetical concerns about it was definitely possible and needed. As stated well in Who’s afraid of OpenAI’s big, bad text generator?:
“The general public likely still believes OpenAI made a text generator so dangerous it couldn’t be released, because that’s what they saw when they scrolled through their news aggregator of choice. But it’s not true, there’s nothing definitively dangerous about this particular text generator. Just like Facebook never developed an AI so dangerous it had to be shut down after inventing its own language. The kernels of truth in these stories are far more interesting than the lies in the headlines about them – but sadly, nowhere near as exciting.
The biggest problem here is that by virtue of on onslaught of misleading headlines, the general public’s perception of what AI can and cannot do is now even further skewed from reality. It’s too late for damage-control, though OpenAI did try to set the record straight.
No amount of slow news reporting can entirely undo the damage that’s done when dozens of news outlets report that an AI system is “too dangerous,” when it’s clearly not the case. It hurts research, destroys media credibility, and distorts politicians’ views.
To paraphrase Anima Anandkumar: I’m not worried about AI-generated fake news, I’m worried about fake news about AI.”
TLDR
GPT-2 is not known to be ‘too dangerous to release’ , even if it might be. Whatever the motives of OpenAI may have been, discussion of how to most responsibly share new technology with a potential for misuse is good — and misleading articles calling largely incremental AI advances ‘dangerous’ are bad. Hopefully, any future ‘experiments’ from OpenAI will results in more of the former and less of the latter.
-
A transformer is a popular new idea for machine learning with language – read more here. A language model is an AI algorithm meant to injest sequences of text and predict what words are most likely to occur next. ↩
-
Generative Pre-Training Transformer 2; an overview of the original GPT model can be read here. ↩
-
Technologies which are designed for civilian purposes but which may have military applications, or more broadly designed for certain beneficial uses but can be abused for negative impacts ↩






