How have DOTA and StarCraft wins advanced AI research?

How have DOTA and StarCraft wins advanced AI research?
Impressive results have been obtained by scaling known techniques, and the long-term prospects remain unclear

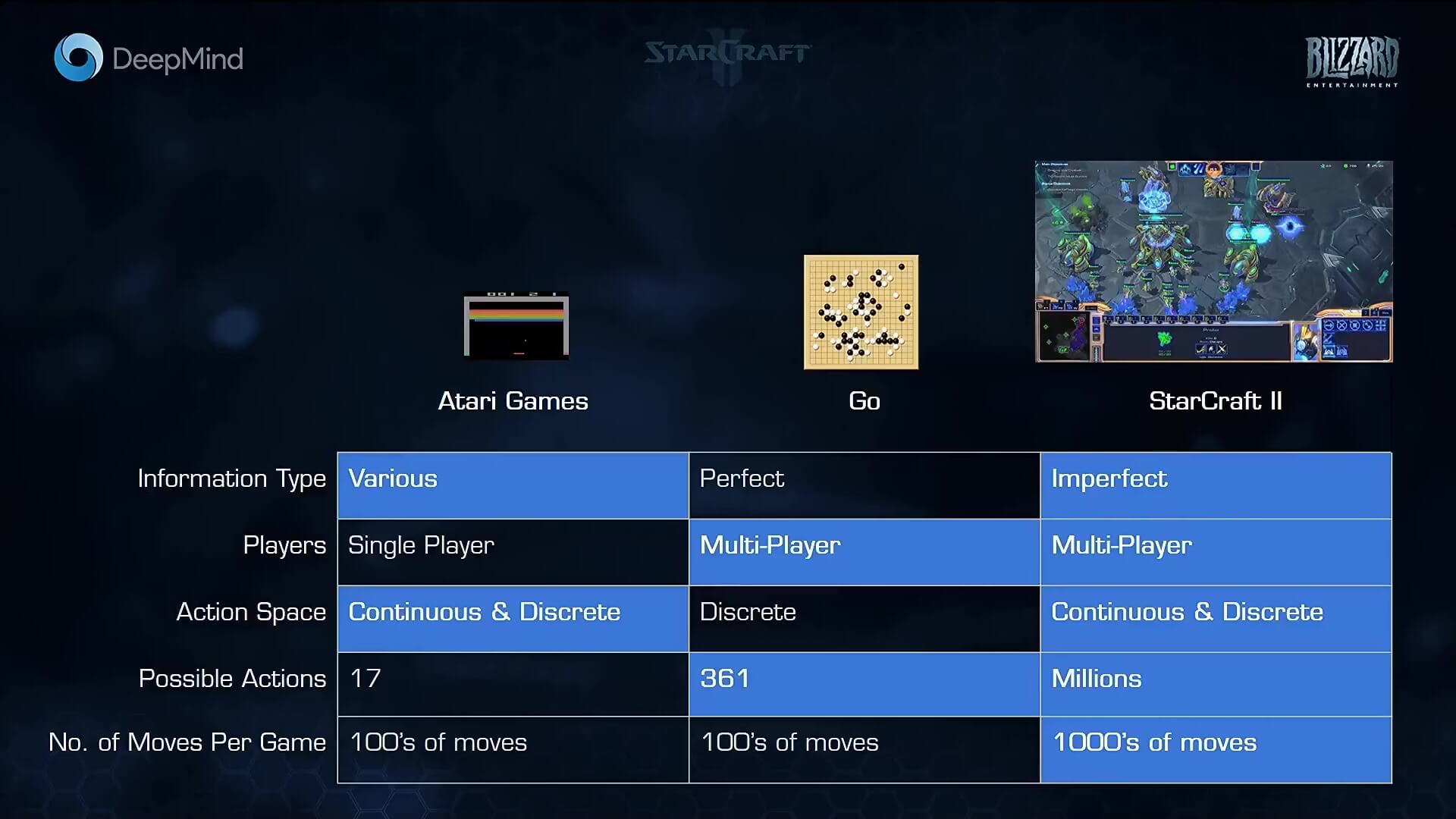
Recently we’ve seen much-hyped public demonstrations of advances in reinforcement learning (RL) with OpenAI (OAI) Five and DeepMind’s (DM) AlphaStar competing against human gamers in DOTA II and StarCraft respectively, and we’re set to see another demonstration on April 13th. It has become a standard trend for research labs and companies to broadcast such achievements with the aim of impressing the general public (and likely investors) as much as contributing to the field of AI research. So, it is important to distinguish the PR from the research progress, and with that in mind we will examine the two achievements in this article. In particular, we will note that both of them were made possible by some simplifications of their respective domains and by scaling-up versions of existing technology rather than groundbreaking new ideas 1.
OpenAI Five at the International

The Open AI Five experiment captured a lot of public attention. First, there was a show match against an ad-hoc team of retired DotA II professional players. This demo hyped up the public because the RL bots won every standard match, suggesting the DotA II agents might beat real pro teams. Not long after, OAI played off against top human professionals in a showcase at the International (a major DotA II annual event). The five RL bots featured impressive team fighting and coordination, but eventually lost each match against the professionals in the “late game” due to a lack of long term strategy. These matches demonstrated some of the incredible strengths and also the yet-unsolved limitations of reinforcement learning.
The major achievements for this work are summarized well by OAI: DOTA II is a problem that is orders of magnitude more difficult than those addressed in prior works due to the number of available actions, number of observations, number of steps in a single game, and the amount of hidden information that must be inferred. But as covered well in Motherboard’s “OpenAI Is Beating Humans at ‘Dota 2’ Because It’s Basically Cheating”, there are several important caveats to be aware of. In order to achieve these results, the OAI team used:
-
API and superhuman speed: The bots were trained using API to get precise game state as thousands of exact numbers, rather than playing by looking at the pixels of the game as humans do. This, and a lack of other restrictions, allows the bots to have ‘superhuman’ accuracy and speed which makes them very hard to beat in head-to-head short term fights that don’t require much long-term strategy.
-
Simplifying some tasks during training: OAI modified properties of the game during training to encourage agents to explore important but possibly challenging strategic decisions (like killing Roshan).
-
Hand-designing the model: The team also designed a complex neural net architecture specifically for the task.
-
Limitations on the game: Especially for the first demonstrations but even for the final one, multiple restrictions were placed on standard gameplay—most notably, the roster of playable characters was reduced.
-
Reward shaping: Perhaps most importantly, OAI made heavy use of reward tuning, a process where short term goals are explicitly rewarded instead of only focusing on winning the game. In simple terms, the OAI team directly encouraged its bots towards learning certain behaviors. This is in contrast to something like AlphaZero that learns its strategies solely from self play and match outcome, which is a much less informative, sparse reward for training.
So, while an impressive achievement, it should be noted it was achieved partially by limiting the game and hard-coding human knowledge in the learning process. And as we will discuss soon, their approach to the problem rested on investing heavily in the same basic techniques used for much simpler problems, rather than trying to invent new techniques more appropriate for this challenging a task.
DeepMind AlphaStar and Team Liquid
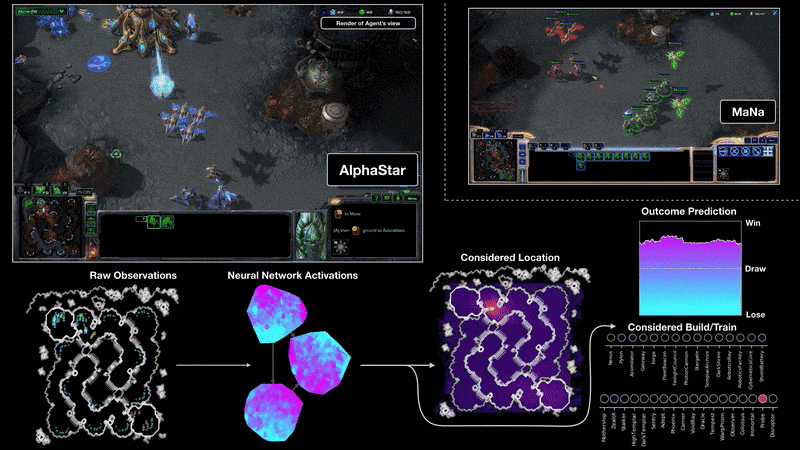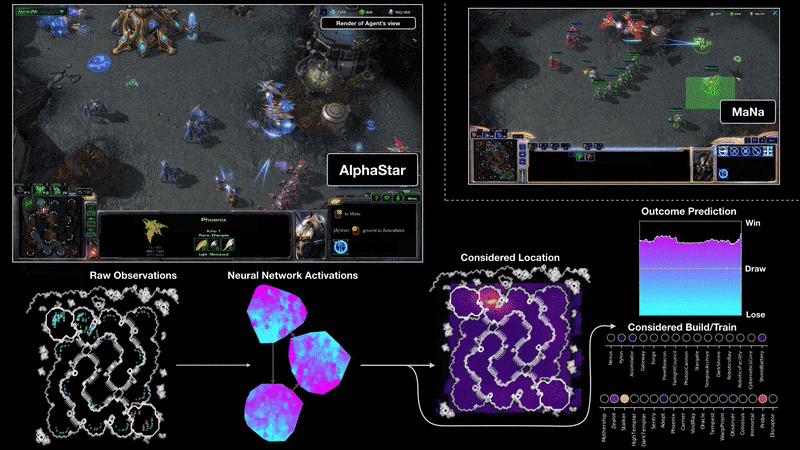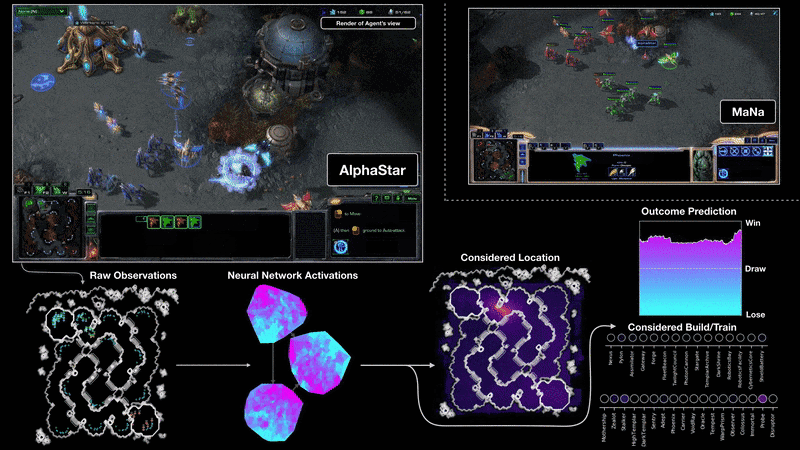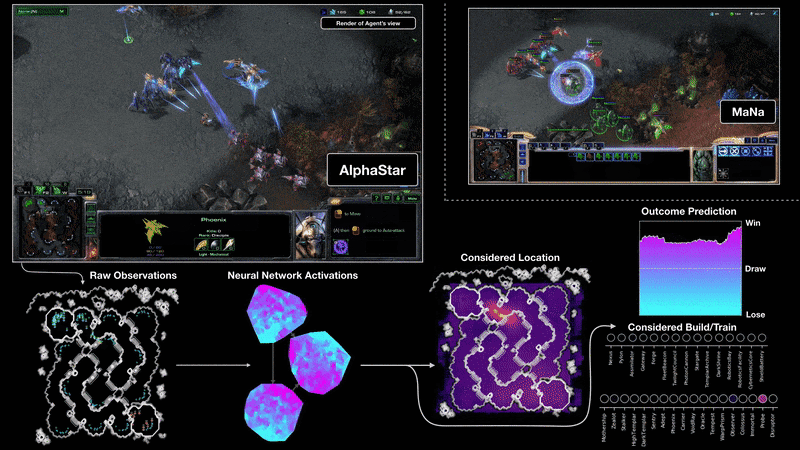

Starcraft II presents another great challenge for reinforcement learning, for largely the same reasons as DOTA II. Earlier this year DM produced a beautiful demonstration of RL research by testing its own set of bots against human professionals. On a broadcasted show, the DM bots beat a human professional 5-0, managing to win in situations in which professionals didn’t think winning was possible. But, as with the OpenAI bots, DM’s prowess was achieved in part by imposing significant limitations on the game, as covered well in “An AI crushed two human pros at StarCraft—but it wasn’t a fair fight”. Most significantly:
-
API and superhuman speed: Like OAI5, DM’s bots were trained with access to exact game state via the game’s API. Although DM did impose some limits on the speed at which the bots could issue actions, analysis of these limitations showed that they still allowed the bots to have the benefit of super-human speed, similarly to the OAI5 bots.
-
Full map observations: the game was much simplified for DM due to it observing the entire game map rather than portions of it at a time as human players do, and when this simplification was taken away in the final match DM lost.
-
Hand-designing the model: as with OAI5, the neural net used in this case was complicated and not general purpose but more specific to the task.
-
Limitations on the game: The bots were also only demonstrated to work on one map, and with one of the three playable races (arguably, the easiest one to master).

Both experiments point to an obvious imminent question, how do we solve the problem of long term planning?
The Algorithms that Brought Us Here
Now we have agents that can play video games! So, is that it? Underneath all this gaming is a guided attempt by researchers to tackle environments with sparse rewards2, large action spaces3, stochasticity4, imperfect information5, and the need for long term planning. Any one of these is an incredibly difficult problem to solve, let alone all of them simultaneously. In simple terms, the best output of the collective research effort in reinforcement learning manifests itself consistently in three steps:
-
Randomly choose actions to explore the environment.
-
Via some model, make an agent remember which actions are better, prefer those.
-
Handcraft the environment, reward, and model to optimize for desired outcome.
This may not sound that impressive to you, so let’s get our hands a little dirtier with details. OAI uses an augmented control policy optimization with memory to attack the DotA II game environment, while DM uses two types of memory, two types of sequential decision making, and a learned reward function estimator to make their agents competitive. Effectively, OAI scaled up an algorithm they implemented and used for smaller problems before, and DM combined several cutting edge ideas into a fairly complicated system. Notice anything missing? No new ideas to deal with abstractions, no reasoning, no semblance of what we understand as the human ability to strategize and plan. OAI and DM instead bet on combining and scaling up existing ideas to tackle these tasks – what we might call engineering.
Not to say these outcomes are not beneficial for AI research; it is good to know how far present day techniques can be pushed and how they can be combined. Still, present day RL research mostly focuses on short term tasks (involving, say sequences of 100s of choices, and not many tens of thousands) and so the bots prowess was indeed in short-term gameplay rather than long term strategy. It is too early to say whether new ideas to deal with strategizing are needed or scaling up is sufficient, but it’s certainly a question to be aware of.
Near Term Hopes and Expectations
For upcoming research in RL, any explicit (or implicit) bridge between short-term and long-term planning could show new promise. It would also be amazing to see new efforts geared towards abstract reasoning within models and a more intuitive specification of objectives. Perhaps these things are out-of-reach given current tools, but progress demands new ideas and effort.
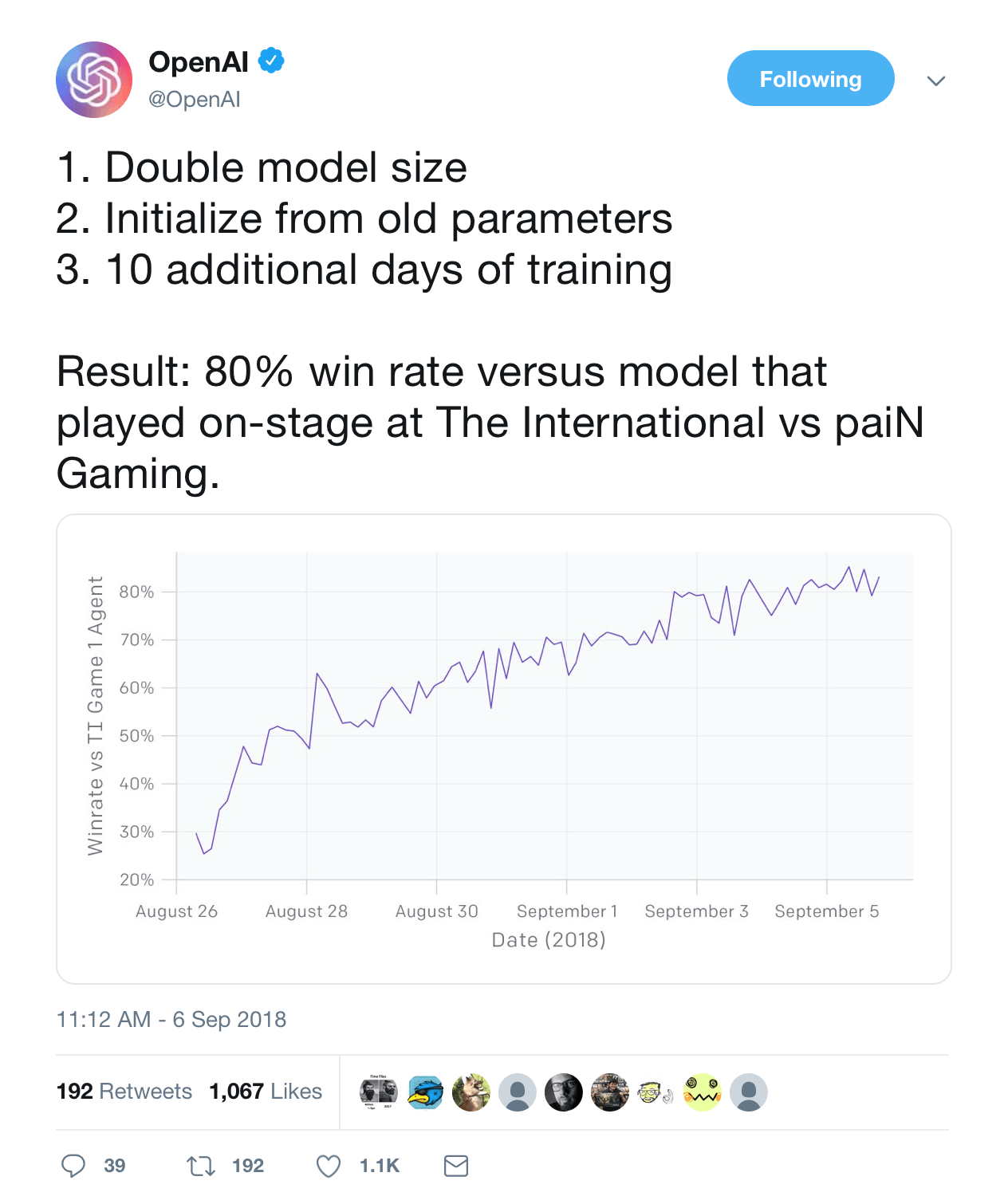
Regarding the upcoming display, it seems unlikely that OAI would schedule another heavily publicized match against professional human players if they expect to lose, they’ll probably win on April 13th. Whether the OAI team has changed the architecture, trained for hundreds (or thousands) more game-years, or fine tuned the reward functions to encourage better long term trajectories, we can expect that this collection of RL agents will look better than the last.
In Summary
All of these reinforcement learning achievements would be difficult to believe a few years ago. The work being done by these research labs is exciting, but not always because of the algorithms involved so much as its scale, effort, and collective public attention. Public efforts such as these inspire the community to put more effort and thought into the underlying steady march towards broadly applicable artificial intelligence. If we keep getting excited as a community and letting the scientific process guide us to new and better algorithms we will get there, but don’t start holding your breath yet.
-
Of course OpenAI and DeepMind definitely are steadily producing promising new algorithmic ideas, as are other large industry AI labs such as Uber Engineering, NVIDIA, and Facebook AI. And, empirical results from scaling current techniques is itself valuable for research, as it shows what’s possible and leads to new valuable insights. ↩
-
Infrequent feedback from the environment about what is good and bad. ↩
-
There are many actions to choose from with continuous value, a very hard problem. ↩
-
The observations and actions each have their own random noise, making prediction more difficult. ↩
-
The entirety of the environment cannot be observed at once, inferences must be made about what is happening. ↩





